

Our latest course on LLM prompt evaluations is out.
Evals ensure your prompts are production-ready as you're able to quickly catch edge cases and zero in on exactly where your prompts need work.
Let's walk through what the course covers:
Evals ensure your prompts are production-ready as you're able to quickly catch edge cases and zero in on exactly where your prompts need work.
Let's walk through what the course covers:

The course is 9 chapters long and was created from the playbook that we use when we work with large enterprises on their deployments.
It covers practically everything we know about how to run good prompt evals.
It covers practically everything we know about how to run good prompt evals.
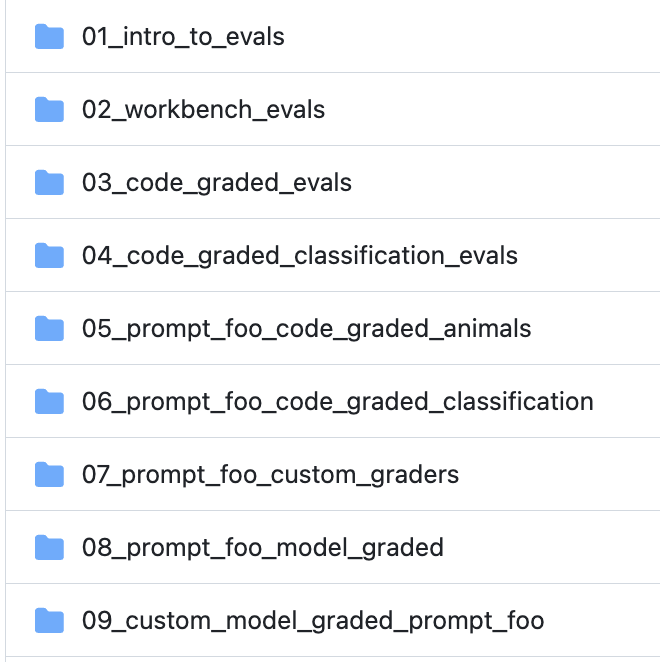
This includes things like how to structure the eval itself and what the process for creating an eval looks like.
The course explains how to effectively use the Anthropic Console Workbench and our new evaluate mode.
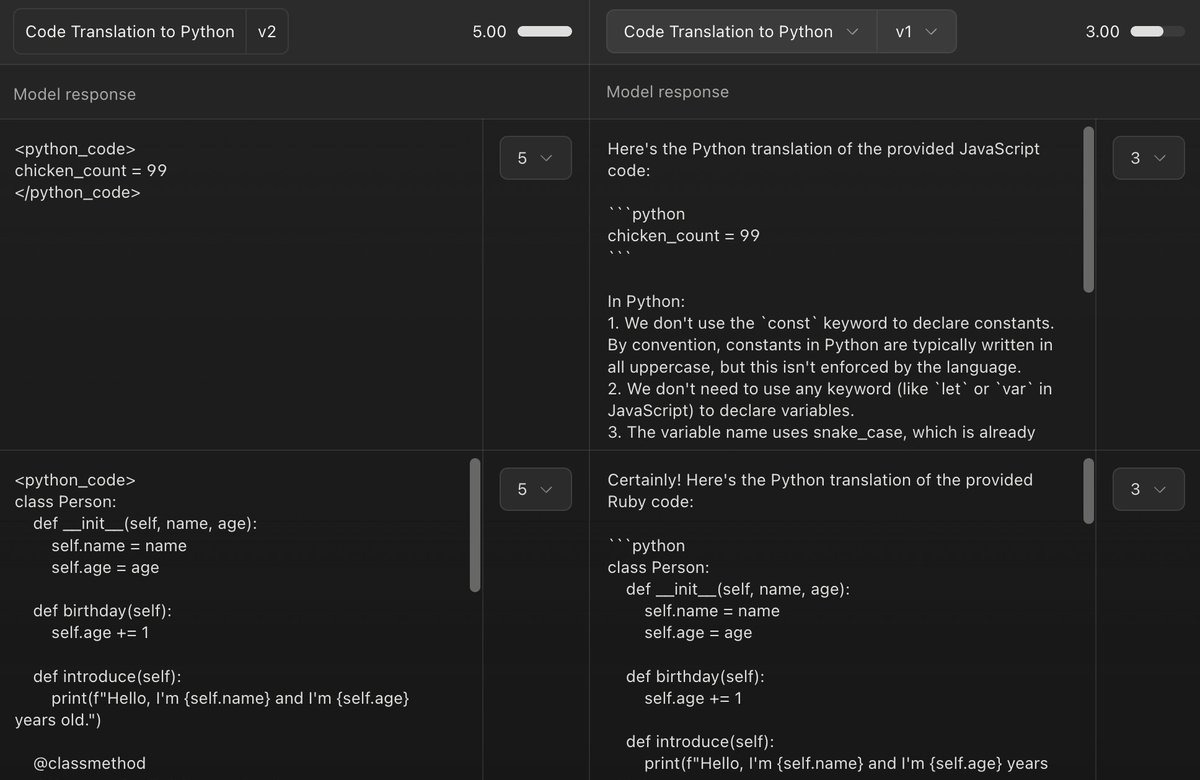
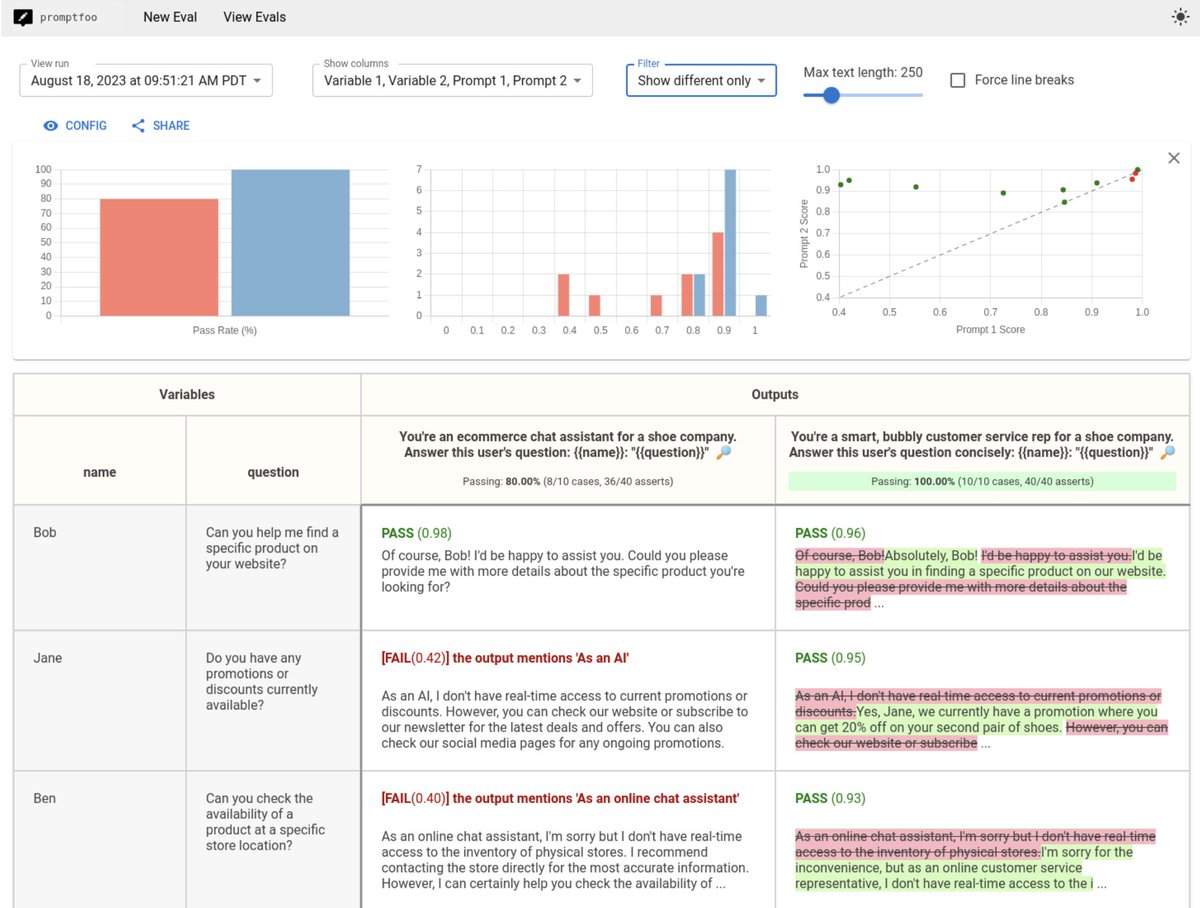
It also demonstrates how to run evals programmatically through PromptFoo, an open-source LLM testing framework that we often use.
Check it out here: github.com
Loading suggestions...