

تغريدات …
عن ،،، كيف تعمل النماذج اللغوية؟
مقدمه
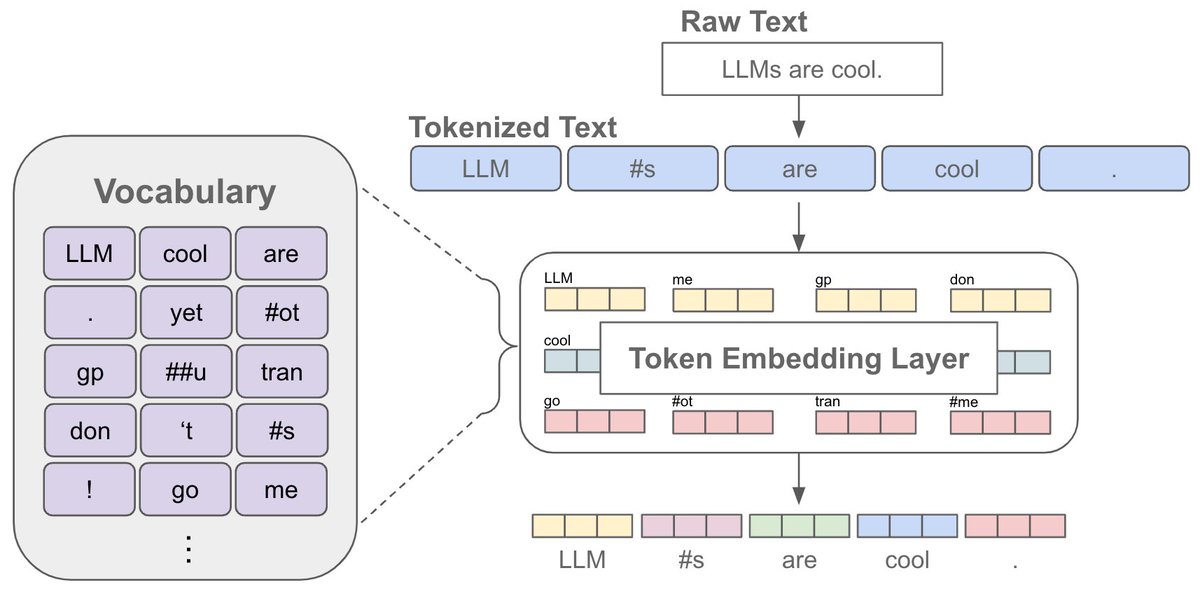
التوكينز (Tokens) أو ما يسمى بالرمز المميز هي وحدات صغيرة من النص يتم تقسيم النصوص الكبيرة إليها لأغراض المعالجة اللغوية بواسطة أجهزة الكمبيوتر. في معالجة اللغات الطبيعية (NLP)، يمكن أن تكون التوكينز كلمات فردية، أو أجزاء من كلمات، أو حتى رموزًا فردية، اعتمادًا على كيفية تصميم النظام للتعامل مع النص.
على سبيل المثال، في جملة مثل “أنا أحب البرمجة”، يمكن تقسيم النص إلى توكينز على شكل كلمات منفصلة: [“أنا”, “أحب”, “البرمجة”]. هذا التمثيل يساعد النماذج اللغوية على تحليل وفهم النص بطريقة أكثر فعالية، حيث يتم التعامل مع كل توكين كعنصر مستقل يمكن معالجته بشكل فردي.
من جانب أخر،،، العملية مرتبطة بالاحتمالات وهذا يتطلب شرح تفصيلي ولكن الشرح في الصورة يمكن أن يوضح الكثير
حسناً، الآن …
ما الذي يحدث في النموذج اللغوي عندما يكون مدرب على كلمة معينة أو غير مدرب عليها؟
قبل الإجابة
عن ،،، كيف تعمل النماذج اللغوية؟
مقدمه
التوكينز (Tokens) أو ما يسمى بالرمز المميز هي وحدات صغيرة من النص يتم تقسيم النصوص الكبيرة إليها لأغراض المعالجة اللغوية بواسطة أجهزة الكمبيوتر. في معالجة اللغات الطبيعية (NLP)، يمكن أن تكون التوكينز كلمات فردية، أو أجزاء من كلمات، أو حتى رموزًا فردية، اعتمادًا على كيفية تصميم النظام للتعامل مع النص.
على سبيل المثال، في جملة مثل “أنا أحب البرمجة”، يمكن تقسيم النص إلى توكينز على شكل كلمات منفصلة: [“أنا”, “أحب”, “البرمجة”]. هذا التمثيل يساعد النماذج اللغوية على تحليل وفهم النص بطريقة أكثر فعالية، حيث يتم التعامل مع كل توكين كعنصر مستقل يمكن معالجته بشكل فردي.
من جانب أخر،،، العملية مرتبطة بالاحتمالات وهذا يتطلب شرح تفصيلي ولكن الشرح في الصورة يمكن أن يوضح الكثير
حسناً، الآن …
ما الذي يحدث في النموذج اللغوي عندما يكون مدرب على كلمة معينة أو غير مدرب عليها؟
قبل الإجابة

متى يكون Tokens دقيقاً؟
تحدد دقة التوكينز تحدد بناءً على حجم المفردات. إذا كانت المفردات أصغر، ستكون الدقة أقل، مما يعني أن النص سيتم تمثيله بتوكينز أكثر عمومية. أما إذا كانت المفردات أكبر، فستكون الدقة أعلى، مما يعني إمكانية تمثيل النص بتوكينز أكثر تحديدًا.
▫️مثال على دقة التوكينز بناءً على حجم المفردات:
حالة 1: مفردات صغيرة (دقة أقل)
في حالة وجود مفردات صغيرة، قد لا تحتوي هذه المفردات على جميع الكلمات والعبارات المركبة. لذلك، يجب تقسيم الكلمات المركبة إلى أجزاء أصغر.
•النص الأصلي: “الذكاء الاصطناعي”
•التوكينز: [“الذكاء”, “الاصطناعي”]
حالة 2: مفردات كبيرة (دقة أعلى)
في حالة وجود مفردات كبيرة تحتوي على عدد أكبر من الكلمات والعبارات المركبة، يمكن للنظام تمثيل النص بتوكينز أكثر تحديدًا.
•النص الأصلي: “الذكاء الاصطناعي”
•التوكينز: [“الذكاء الاصطناعي”]
✔️تفسير
•في الحالة الأولى، بسبب صغر حجم المفردات، لم يتمكن النظام من العثور على الكلمة المركبة “الذكاء الاصطناعي” كتوكينز واحد، فقام بتقسيمها إلى كلمتين منفصلتين، مما أدى إلى دقة أقل.
•في الحالة الثانية، بسبب كبر حجم المفردات، تمكن النظام من تمثيل العبارة كاملة كتوكينز واحد، مما أدى إلى دقة أعلى.
تحدد دقة التوكينز تحدد بناءً على حجم المفردات. إذا كانت المفردات أصغر، ستكون الدقة أقل، مما يعني أن النص سيتم تمثيله بتوكينز أكثر عمومية. أما إذا كانت المفردات أكبر، فستكون الدقة أعلى، مما يعني إمكانية تمثيل النص بتوكينز أكثر تحديدًا.
▫️مثال على دقة التوكينز بناءً على حجم المفردات:
حالة 1: مفردات صغيرة (دقة أقل)
في حالة وجود مفردات صغيرة، قد لا تحتوي هذه المفردات على جميع الكلمات والعبارات المركبة. لذلك، يجب تقسيم الكلمات المركبة إلى أجزاء أصغر.
•النص الأصلي: “الذكاء الاصطناعي”
•التوكينز: [“الذكاء”, “الاصطناعي”]
حالة 2: مفردات كبيرة (دقة أعلى)
في حالة وجود مفردات كبيرة تحتوي على عدد أكبر من الكلمات والعبارات المركبة، يمكن للنظام تمثيل النص بتوكينز أكثر تحديدًا.
•النص الأصلي: “الذكاء الاصطناعي”
•التوكينز: [“الذكاء الاصطناعي”]
✔️تفسير
•في الحالة الأولى، بسبب صغر حجم المفردات، لم يتمكن النظام من العثور على الكلمة المركبة “الذكاء الاصطناعي” كتوكينز واحد، فقام بتقسيمها إلى كلمتين منفصلتين، مما أدى إلى دقة أقل.
•في الحالة الثانية، بسبب كبر حجم المفردات، تمكن النظام من تمثيل العبارة كاملة كتوكينز واحد، مما أدى إلى دقة أعلى.
حسناً…
ماذا يحدث عندما لا تكون الكلمة أو العبارة ضمن Tokens؟
باختصار سوف يلجأ النموذج اللغوي إلى التجزئة
عندما لا تكون الكلمة أو العبارة موجودة في مفردات Tokens، يجب تقسيمها إلى أجزاء أصغر تكون موجودة في المفردات. كلما كانت المفردات أصغر، زادت احتمالية تقسيم الكلمات أو العبارات إلى توكينز متعددة.
مثال
نفترض أن كلمة Chattalk موجودة في مفردات Gemini ولكنها غير موجودة في مفردات GPT-4. عند تقسيم كلمة “Chattalk”:
•Gemini سيمثلها كتوكينز واحد، [Chattalk] لأنها موجودة فيه.
•بينما GPT-4 بسبب صغر مفرداته، قد لا يكون لديه “Chattalk” كتوكينز واحد، بل قد يقسمها إلى توكينز اثنين، [chat] و [talk].
كلما قلت مفردات النموذج اللغوي ترتفع لديه احتمالية تجزئة الكلمات لأنه يواجه كلمات وعبارات غير موجوده ضمن مفرداته وهذه التجزئة ترفع من عدد Tokens وهذا بدوره يؤدي إلى نتائج أخرى مثل:
- زيادة حجم البيانات المعالجة وبالتالي يزيد وقت المعالجة.
- ارتفاع نسبة الخطأ بسبب زيادة تعقيد التحليل والربط بين Tokens
- ارتفاع التكلفة المحسوبة من استخدام عدد الـ Tokens كما هو الحال في OpenAI و غيرها.
ماذا يحدث عندما لا تكون الكلمة أو العبارة ضمن Tokens؟
باختصار سوف يلجأ النموذج اللغوي إلى التجزئة
عندما لا تكون الكلمة أو العبارة موجودة في مفردات Tokens، يجب تقسيمها إلى أجزاء أصغر تكون موجودة في المفردات. كلما كانت المفردات أصغر، زادت احتمالية تقسيم الكلمات أو العبارات إلى توكينز متعددة.
مثال
نفترض أن كلمة Chattalk موجودة في مفردات Gemini ولكنها غير موجودة في مفردات GPT-4. عند تقسيم كلمة “Chattalk”:
•Gemini سيمثلها كتوكينز واحد، [Chattalk] لأنها موجودة فيه.
•بينما GPT-4 بسبب صغر مفرداته، قد لا يكون لديه “Chattalk” كتوكينز واحد، بل قد يقسمها إلى توكينز اثنين، [chat] و [talk].
كلما قلت مفردات النموذج اللغوي ترتفع لديه احتمالية تجزئة الكلمات لأنه يواجه كلمات وعبارات غير موجوده ضمن مفرداته وهذه التجزئة ترفع من عدد Tokens وهذا بدوره يؤدي إلى نتائج أخرى مثل:
- زيادة حجم البيانات المعالجة وبالتالي يزيد وقت المعالجة.
- ارتفاع نسبة الخطأ بسبب زيادة تعقيد التحليل والربط بين Tokens
- ارتفاع التكلفة المحسوبة من استخدام عدد الـ Tokens كما هو الحال في OpenAI و غيرها.

جاري تحميل الاقتراحات...