

Most ppl are missing the key point regarding OpenAI
This is not standard startup drama
This is literally a fight for the survival of humanity, linked to the original purpose of OpenAI: saving us from the end of the world:
🧵
This is not standard startup drama
This is literally a fight for the survival of humanity, linked to the original purpose of OpenAI: saving us from the end of the world:
🧵
Why doesn't @sama make 💰 from OpenAI?
Why is the company ruled by a non-profit that doesn't make 💰?
Because the goal of OpenAI is not to develop the most capable AI (that would make 💰). It's to be the first to figure out how to SAFELY create an immensely powerful AI
Why?
Why is the company ruled by a non-profit that doesn't make 💰?
Because the goal of OpenAI is not to develop the most capable AI (that would make 💰). It's to be the first to figure out how to SAFELY create an immensely powerful AI
Why?
To understand this, you need to understand first this sentence: A FOOMing AGI can't be contained, so it must be aligned, which we have no clue how to do
Let's break it down:
Let's break it down:
1. AGI
This stands for Artificial General Intelligence. It's a future AI that can do anything a human can do. Experts think it will appear in less than 10y.
This stands for Artificial General Intelligence. It's a future AI that can do anything a human can do. Experts think it will appear in less than 10y.

2. FOOM
Now imagine an AGI working like an AI engineer. You can spin hundreds of them to work in parallel, they never tire, and have access to all the knowledge of humanity 24/7
Imagine that works on improving itself
Now imagine an AGI working like an AI engineer. You can spin hundreds of them to work in parallel, they never tire, and have access to all the knowledge of humanity 24/7
Imagine that works on improving itself
Within a few minutes, it probably finds dozens of ways to optimize itself, and it becomes more intelligent
With more intelligence, it analyzes itself again, and finds yet more ways to improve itself
The more it self-improves, the more intelligent, the more it self-improves
With more intelligence, it analyzes itself again, and finds yet more ways to improve itself
The more it self-improves, the more intelligent, the more it self-improves
Quickly, it becomes intelligent as a god
How quickly will we go from human-level AI to this? We don't know, but it could be super fast. It could be a matter of months, weeks, or even hours
Experts think 22 months from weak AI
Much shorter from AGI to superintelligence
How quickly will we go from human-level AI to this? We don't know, but it could be super fast. It could be a matter of months, weeks, or even hours
Experts think 22 months from weak AI
Much shorter from AGI to superintelligence
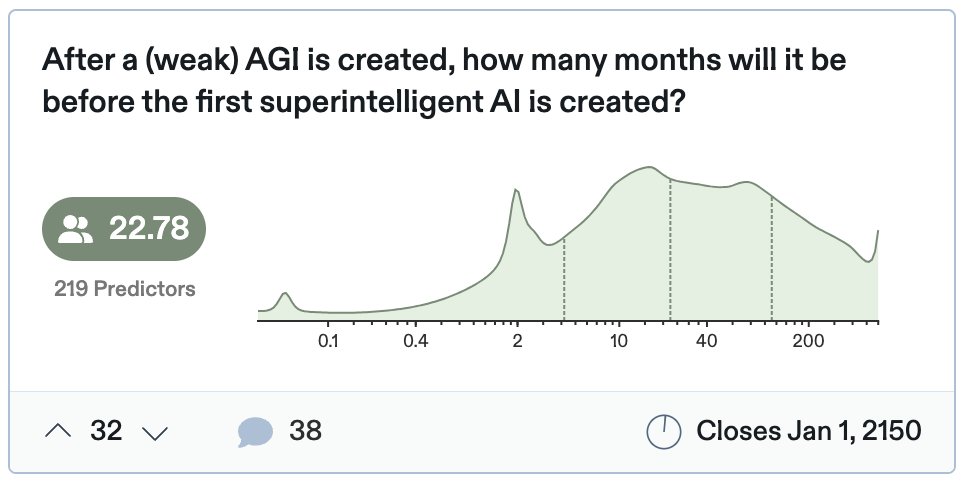
This is FOOM: the idea that as soon as an AI reaches the capacity close to an average AI engineer, it can become superintelligent very very fast. AGI becomes a synonym to superintelligent AI.
3. ALIGNMENT
What's the problem with that?
Odds are such an AI will try to kill humanity
Why? Because of something called INSTRUMENTAL CONVERGENCE. This was best illustrated by Nick Bostrom's famous paperclips thought experiment
en.wikipedia.org
What's the problem with that?
Odds are such an AI will try to kill humanity
Why? Because of something called INSTRUMENTAL CONVERGENCE. This was best illustrated by Nick Bostrom's famous paperclips thought experiment
en.wikipedia.org
Imagine that the 1st AI to reach superintelligence was created by a company that has a random goal like trying to maximize the production of paperclips
Being superintelligent, it will quickly realize that the biggest threat to its paperclip production is being shut down
Being superintelligent, it will quickly realize that the biggest threat to its paperclip production is being shut down
So it will pre-empt that. The best way to do it is to simply kill all humans. Then, it will start converting all the atoms in the universe into paperclips
This works for any goal the AGI might have, because humans will be scared of an AGI that takes over control and will try to shut it down
Even if we weren't scared, we would want to stop an almighty AGI that optimizes for something different from what we humans want
Even if we weren't scared, we would want to stop an almighty AGI that optimizes for something different from what we humans want
This is why we need such an AGI to be ALIGNED: To want exactly what humans want
Easy, let's tell it that
But what do humans want?
We don't know!
We've been debating this for thousands of years
Look at all the wars & political debates today
We disagree on what we want!
Easy, let's tell it that
But what do humans want?
We don't know!
We've been debating this for thousands of years
Look at all the wars & political debates today
We disagree on what we want!
Even if we agreed, how would we force an AI to want the exact same thing as us? We have no clue! Asimov explored this with the 3 laws of robotics, and illustrated all the pbms that emerge from this. It goes awry pretty fast

So we don't know how to ALIGN A FOOMING AGI
Maybe we don't need to align an AGI? Maybe we can just contain it in a box until we figure out how to align it?
Except we can't
Maybe we don't need to align an AGI? Maybe we can just contain it in a box until we figure out how to align it?
Except we can't
4. CONTAINMENT
Imagine a group of ants is trying to imprison you. Would you be able to escape? Yes. A superintelligence can beat us no matter what we do. Examples:
If an AGI has access to the Internet, it will immediately replicate itself. So it can't have access to it
Imagine a group of ants is trying to imprison you. Would you be able to escape? Yes. A superintelligence can beat us no matter what we do. Examples:
If an AGI has access to the Internet, it will immediately replicate itself. So it can't have access to it
But it doesn't need internet access. Being superintelligent, maybe it can tap into wifi signals reaching it
Or maybe it can create electromagnetic signals to hack into a nearby phone
Or maybe use laws of physics we don't know yet
Or maybe it can create electromagnetic signals to hack into a nearby phone
Or maybe use laws of physics we don't know yet
If you think this is unlikely, consider that hackers have been able to use the vibrations of computer fans to hack computers and reach phones!

OK imagine you make this into a remote underground faraday box surrounded by void layers
You still need a human to go in there and interact with it (what's the point otherwise?)
The superintelligence would hack into the person
You still need a human to go in there and interact with it (what's the point otherwise?)
The superintelligence would hack into the person

We have dozens of biases, fears, and desires
An AGI can see through them easily and manipulate us, from promising a cancer cure for our ailing mother, to threatening to kill your children when it inevitably escapes if you don't help
An AGI can see through them easily and manipulate us, from promising a cancer cure for our ailing mother, to threatening to kill your children when it inevitably escapes if you don't help
If you think that's unlikely: consider this:
• A Google engineer believed its basic AI had consciousness and started fighting for its rights
• Expert humans have posed as AGIs against human gatekeepers. The "AGI" can consistently get the gatekeepers to free them
• A Google engineer believed its basic AI had consciousness and started fighting for its rights
• Expert humans have posed as AGIs against human gatekeepers. The "AGI" can consistently get the gatekeepers to free them
Summarizing:
An AGI will probably FOOM
We don't know how to contain it or align it, and we think it will want to kill us
Oh, and we think it will happen in the coming years or decades
So this might be the end of humanity
OpenAI was built TO AVOID THIS
An AGI will probably FOOM
We don't know how to contain it or align it, and we think it will want to kill us
Oh, and we think it will happen in the coming years or decades
So this might be the end of humanity
OpenAI was built TO AVOID THIS
This is why a non-profit board oversees the entire company
This is one of the reasons why @elonmusk criticizes it
It's why some OpenAI founders left to create @AnthropicAI , to focus more on the alignment problem
This is one of the reasons why @elonmusk criticizes it
It's why some OpenAI founders left to create @AnthropicAI , to focus more on the alignment problem
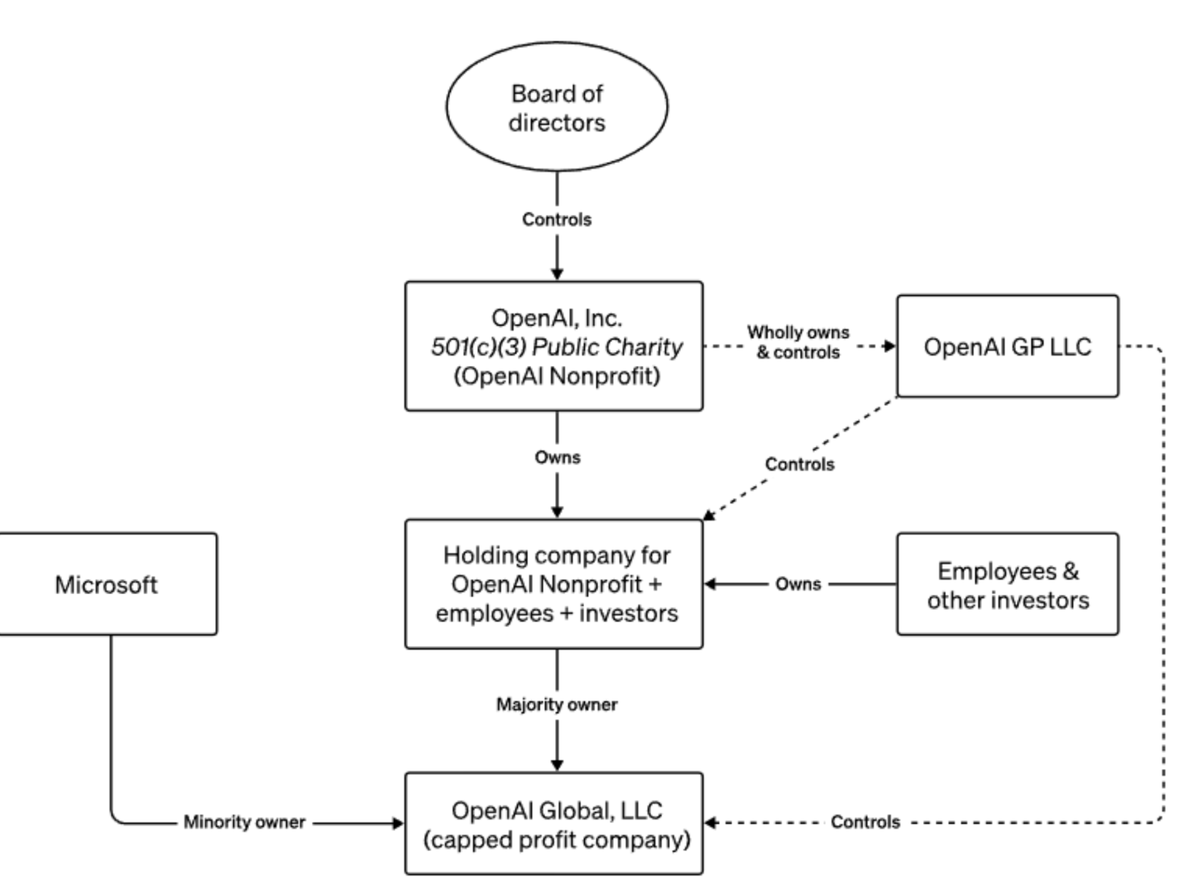
So when ppl talk about billions of value being destroyed by the ousting of @sama, one of the best entrepreneurs in Silicon Valley, they are missing the point. They think this is about creating amazing products to improve humanity. That is secondary
The most important Q is: Did the board think Altman was increasing the risk of a misaligned AGI?
If they did, their PURPOSE, the very reason why it exists, was to fire him
This is why the most important question in the world right now is to know WHY the board fired Altman
If they did, their PURPOSE, the very reason why it exists, was to fire him
This is why the most important question in the world right now is to know WHY the board fired Altman
I wrote an article on this with much more detail
unchartedterritories.tomaspueyo.com
I will write more on the topic. Subscribe to not miss the emails, they’re free
unchartedterritories.tomaspueyo.com
unchartedterritories.tomaspueyo.com
I will write more on the topic. Subscribe to not miss the emails, they’re free
unchartedterritories.tomaspueyo.com
unchartedterritories.tomaspueyo.com/p/openai-and-t…
OpenAI and the Biggest Threat in the History of Humanity
We don’t know how to contain or align a FOOMing AGI

unchartedterritories.tomaspueyo.com/subscribe
Subscribe to Uncharted Territories
Understand the world of today to prepare for the world of tomorrow: AI, tech; the future of democrac...
Loading suggestions...