

تقسيم البيانات إلى بيانات تدريب training وتحقق validation و اختبار testing
تعتبر من المفاهيم الأساسية في تعلم الآلة. لكن عدة مرات يتكرر علي هذا السؤال ويذكر بعضهم أنه تكرر عليه في كذا مقابلة.
في هذه التغريدات سأحاول توضيح لماذا نستخدمها والفروق بينهم.
تعتبر من المفاهيم الأساسية في تعلم الآلة. لكن عدة مرات يتكرر علي هذا السؤال ويذكر بعضهم أنه تكرر عليه في كذا مقابلة.
في هذه التغريدات سأحاول توضيح لماذا نستخدمها والفروق بينهم.

بعد التعريفات هناك بعض الأسئلة التي سأحاول الإجابة عليها
ماهي النسبة الأفضل لتقسيم البيانات ٨٠٪ تدريب و ٢٠٪ إختبار. أو ٣٠:٧٠ أو ١٠:٩٠؟
ماهي طرق تقسيم البيانات أو كيف يتم التقسيم؟
إذا كان لدينا عدم موازنة في الكلاسات كيف نحلها؟
متى أستخدم التقسيم العادي أو cross validation؟
ماهي النسبة الأفضل لتقسيم البيانات ٨٠٪ تدريب و ٢٠٪ إختبار. أو ٣٠:٧٠ أو ١٠:٩٠؟
ماهي طرق تقسيم البيانات أو كيف يتم التقسيم؟
إذا كان لدينا عدم موازنة في الكلاسات كيف نحلها؟
متى أستخدم التقسيم العادي أو cross validation؟
في البداية بناء نموذج تعلم آلي ليست عملية واحدة حتى نصل لنتيجة مُرضية. نحتاج أن نجرب عدة خوارزميات وعدة إعدادات لكل خوارزمية حتى نصل لأفضل نموذج Final Model
هذه العملية تسمى Model Selection. وفيها بعض التفاصيل والاستراتجيات المختلفة لكن نركز على حالتين:
هذه العملية تسمى Model Selection. وفيها بعض التفاصيل والاستراتجيات المختلفة لكن نركز على حالتين:
لنفرض لدينا مشكلة classification
ولدينا ٣ خوارزميات مُرشحةKNN, SVM, and Decision Tree
فالاختيار من بينها هذه الحالة الأولى
واختيار الإعدادات أو المتغيرات الأفضل في نفس الخوارزمية هذه الحالة الثانية
فمثلاً ال kernl في SVM أفضل أن نستخدم rbf أو linear
يسمى hyperparameter tuning
ولدينا ٣ خوارزميات مُرشحةKNN, SVM, and Decision Tree
فالاختيار من بينها هذه الحالة الأولى
واختيار الإعدادات أو المتغيرات الأفضل في نفس الخوارزمية هذه الحالة الثانية
فمثلاً ال kernl في SVM أفضل أن نستخدم rbf أو linear
يسمى hyperparameter tuning
لذلك يتم استخدام البيانات لتدريب كل خوارزمية بشكل مستقل ونختار الأفضل
وأيضاً نستخدم البيانات لنحصل على أفضل متغيرات للخوارزمية المُختارة
وأيضاً نستخدم البيانات لنحصل على أفضل متغيرات للخوارزمية المُختارة
بعد المقدمة البسيطة نُعرف:
بيانات التدريب Training set
هي الجزء الأكبر من ال dataset حيث تستخدم لتدريب النموذج. بمعنى أن أُدخل صورة لحرف أ للنموذج وهو يعرف أنه الحرف أ كما في ال Supervised learning
فيحاول النموذج من خلال هذه البيانات أكتشاف العلاقة التي تمكنه من التنبؤ بشكل صحيح
بيانات التدريب Training set
هي الجزء الأكبر من ال dataset حيث تستخدم لتدريب النموذج. بمعنى أن أُدخل صورة لحرف أ للنموذج وهو يعرف أنه الحرف أ كما في ال Supervised learning
فيحاول النموذج من خلال هذه البيانات أكتشاف العلاقة التي تمكنه من التنبؤ بشكل صحيح
بيانات التحقق Validation set
تستخدم للتحقق من النموذج أثناء عملية التدريب بحيث يتم ضبط المتغيرات واختيار أفضل نموذج
إذا كان لدينا خوارزمية واحدة فقط ولا نحتاج ضبط المتغيرات لها - وهذا نادر- فقد نستغني على بيانات التحقق validation
تستخدم للتحقق من النموذج أثناء عملية التدريب بحيث يتم ضبط المتغيرات واختيار أفضل نموذج
إذا كان لدينا خوارزمية واحدة فقط ولا نحتاج ضبط المتغيرات لها - وهذا نادر- فقد نستغني على بيانات التحقق validation
بيانات الاختبار Testing set
تستخدم لتقييم النموذج النهائي على بيانات المُفترض أنها مجهولة ولم يشاهدها النمودج unseen أثناء التدريب. حيث نتحقق أنه يمكننا تعميم النموذج Generalization
تستخدم لتقييم النموذج النهائي على بيانات المُفترض أنها مجهولة ولم يشاهدها النمودج unseen أثناء التدريب. حيث نتحقق أنه يمكننا تعميم النموذج Generalization
إذا بالمختصر بيانات التدريب تستخدم لتدريب النموذج 😊. وبيانات التحقق لتقييم النموذج أثناء التدريب لضبط المتغيرات واختيار أفضل نموذج. بيانات الاختبار لتقييم النموذج النهائي- بعد التدريب- وتعميمه.
إذاً لدينا ٣ خوارزميات. وقسمنا البيانات إلى تدريب/تحقق/اختبار من خلال مثلا دالة train_test_split في بايثون
تم استخدام بيانات التدريب لتدريبهم. ثم بيانات التحقق لاختيار أفضلهم وضبط المتغيرات.
وبيانات الاختبار لتقييم أفضل نمودج final model حصلنا عليه.
تم استخدام بيانات التدريب لتدريبهم. ثم بيانات التحقق لاختيار أفضلهم وضبط المتغيرات.
وبيانات الاختبار لتقييم أفضل نمودج final model حصلنا عليه.
في بعض الحالات لا تكفي البيانات لهذه العملية.
حيث التقسيم لثلاث مجموعات غير مناسب. فيتم استخدام التحقق المتقاطع cross validation من خلال GridSearchCV لضبط المتغيرات واختيار أفضل نموذج.
ال cv لها عدة أنواع فمثلا ال k-folds
حيث التقسيم لثلاث مجموعات غير مناسب. فيتم استخدام التحقق المتقاطع cross validation من خلال GridSearchCV لضبط المتغيرات واختيار أفضل نموذج.
ال cv لها عدة أنواع فمثلا ال k-folds
لنفرض ال k يساوي ٥. فيكون لدينا ٥ تجارب أو iterations
في كل مرة مجموعة كبيرة من البيانات تُستخدم للتدريب وجزء يستخدم للاختبار. بمعنى نستخدم البيانات نفسها لكن بمجموعات مختلفة للتدريب والاختبار
في كل مرة مجموعة كبيرة من البيانات تُستخدم للتدريب وجزء يستخدم للاختبار. بمعنى نستخدم البيانات نفسها لكن بمجموعات مختلفة للتدريب والاختبار
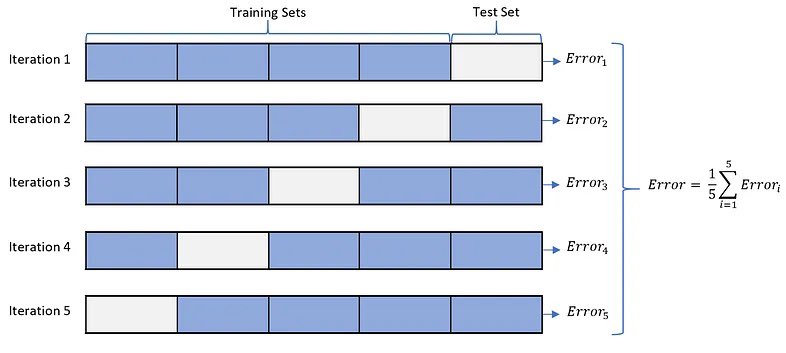
نأتي لبعض الأسئلة.
ماهي النسبة الأفضل لتقسيم البيانات ٨٠٪ تدريب و ٢٠٪ إختبار. أو ٣٠:٧٠ أو ١٠:٩٠؟
لا يوجد إجابة محددة فهي حسب البيانات.
قد يكون أشهرها ٢٠:٨٠ أو ما يسمى Pareto principle
ماهي النسبة الأفضل لتقسيم البيانات ٨٠٪ تدريب و ٢٠٪ إختبار. أو ٣٠:٧٠ أو ١٠:٩٠؟
لا يوجد إجابة محددة فهي حسب البيانات.
قد يكون أشهرها ٢٠:٨٠ أو ما يسمى Pareto principle
ماهي طرق التقسيم أو كيف يتم التقسيم؟
يوجد عدة طرق من ضمنها:
١- نستخدم التقسيم اليدوي وهذي لا ينصح به لانه قد يسبب تحيز لكلاس معين
٢- دوال التقسيم مثلا train_test_split
٣- ال cv وهذي فيها أشكال مختلفة
يوجد عدة طرق من ضمنها:
١- نستخدم التقسيم اليدوي وهذي لا ينصح به لانه قد يسبب تحيز لكلاس معين
٢- دوال التقسيم مثلا train_test_split
٣- ال cv وهذي فيها أشكال مختلفة
إذا كان لدينا عدم موازنة في الكلاسات كيف نحلها؟
عدم الموازنة بمعنى إذا عندنا ١٠٠ عينة ٩٠ منها للكلاس A و ١٠ لكلاس B. التقسيم train_test_split قد تسبب أن بيانات الاختبار قد تكون جميعها لكلاس A
أحد الحلول نستخدم stratify
عدم الموازنة بمعنى إذا عندنا ١٠٠ عينة ٩٠ منها للكلاس A و ١٠ لكلاس B. التقسيم train_test_split قد تسبب أن بيانات الاختبار قد تكون جميعها لكلاس A
أحد الحلول نستخدم stratify

متى أستخدم التقسيم العادي أو cv؟
في الغالب إذا كانت البيانات كثيرة يستخدم التقسيم العادي وإذا كانت قليلة يستخدم cv.
في الغالب إذا كانت البيانات كثيرة يستخدم التقسيم العادي وإذا كانت قليلة يستخدم cv.
يمكن الدمج بينهم.عدد من الممارسات تُفضل الطريقة التالية:
١-تقسم البيانات لنفرض ٨٠٪ تدريب و ٢٠٪ إختبار
٢-يتم تطبيق ال cv على بيانات التدريب فقط. بحيث تكون بيانات تدريب وتحقق حسب ال folds
ويتم هنا ضبط المتغيرات واختيار أفضل نموذج
٣-يتم تقييم النموذج النهائي من خلال بيانات الاختبار
١-تقسم البيانات لنفرض ٨٠٪ تدريب و ٢٠٪ إختبار
٢-يتم تطبيق ال cv على بيانات التدريب فقط. بحيث تكون بيانات تدريب وتحقق حسب ال folds
ويتم هنا ضبط المتغيرات واختيار أفضل نموذج
٣-يتم تقييم النموذج النهائي من خلال بيانات الاختبار
الممارسات مختلفة وكل نموذج أو بيانات لها طريقة تناسبها. البعض يُفضل الممارسة الأخيرة بحيث تكون بيانات الاختبار مفصولة تماماً عن التدريب. حتى لو كانت البيانات قليلة يوجد طرق لزيادة البيانات.
الخلاصة بعض هذه المفاهيم فيها الكثير من التفاصيل لكن حاولت توضيحها بشكل مختصر.
الخلاصة بعض هذه المفاهيم فيها الكثير من التفاصيل لكن حاولت توضيحها بشكل مختصر.
جاري تحميل الاقتراحات...