

Say you wanted to run a chatGPT-sized language model on your desktop.
Not possible.
Until now. (Unless you wanted to wait a minute and a half for each word.)
This paper figures out how to do it on a single GPU at 1 token per second
github.com
Not possible.
Until now. (Unless you wanted to wait a minute and a half for each word.)
This paper figures out how to do it on a single GPU at 1 token per second
github.com
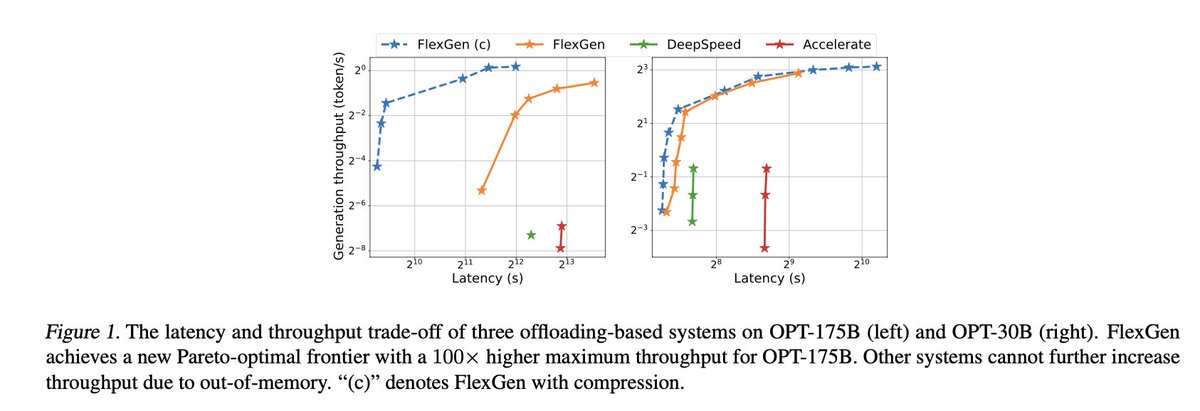
Efficiently offloading the model into lower cost memory also reduces cost per token.
Sure, it's not as fast as cloud-inferring on $200k worth of GPUs, but it reduces cost per token generated by 75%
Sure, it's not as fast as cloud-inferring on $200k worth of GPUs, but it reduces cost per token generated by 75%

(That the cost is realized against a home system rather than via cloud-billing, also significantly opens up the economic model.)
(And while a token per second is not *blazingly* fast, it will allow the open source community to more easily experiment and optimize.)
(And while a token per second is not *blazingly* fast, it will allow the open source community to more easily experiment and optimize.)
(note paper link in the original GitHub repository was down, so I linked off a fork; original GitHub repository is here: github.com)
Loading suggestions...