

(ثريد)
قد سمعتو بمصطلح البيانات الكبيرة؟
وجا على بالكم طالما هي كبيرة كيف ممكن اننا نحلل ونتعامل مع البيانات هاذي؟ وايش علاقتها بـSpark؟
هل جربت تسوي load لملف csv فيه 50 او 80 مليون صف و 70 عمود؟
قد سمعتو بمصطلح البيانات الكبيرة؟
وجا على بالكم طالما هي كبيرة كيف ممكن اننا نحلل ونتعامل مع البيانات هاذي؟ وايش علاقتها بـSpark؟
هل جربت تسوي load لملف csv فيه 50 او 80 مليون صف و 70 عمود؟

1
تخيلو معايا عندكم بيانات ويستوعبها الجهاز العادي في رام او ميموري 32 او 64 قيقا...
هاذي البيانات ما تصنف انها بيانات ضخمة ولكن لو حبينا نخزن بيانات اكبر من هاذي السعة فين ممكن نخزنها؟
تخيلو معايا عندكم بيانات ويستوعبها الجهاز العادي في رام او ميموري 32 او 64 قيقا...
هاذي البيانات ما تصنف انها بيانات ضخمة ولكن لو حبينا نخزن بيانات اكبر من هاذي السعة فين ممكن نخزنها؟
2
اما نخزنها في:-
-DB
-Hard Drive
-Distributed Systems
وهنا يجي دور Spark ,,,
وفي حال لقيت نفسك في يوم انك مضطر تستخدم Spark فانت في نقطة لا يمكن فيها انك تستخدم راماتك او جهازك لتخزين البيانات.
اما نخزنها في:-
-DB
-Hard Drive
-Distributed Systems
وهنا يجي دور Spark ,,,
وفي حال لقيت نفسك في يوم انك مضطر تستخدم Spark فانت في نقطة لا يمكن فيها انك تستخدم راماتك او جهازك لتخزين البيانات.
3
طيب قبل كل شي خلونا نعرف ايش يعني :
Local Systems & Distributed Systems
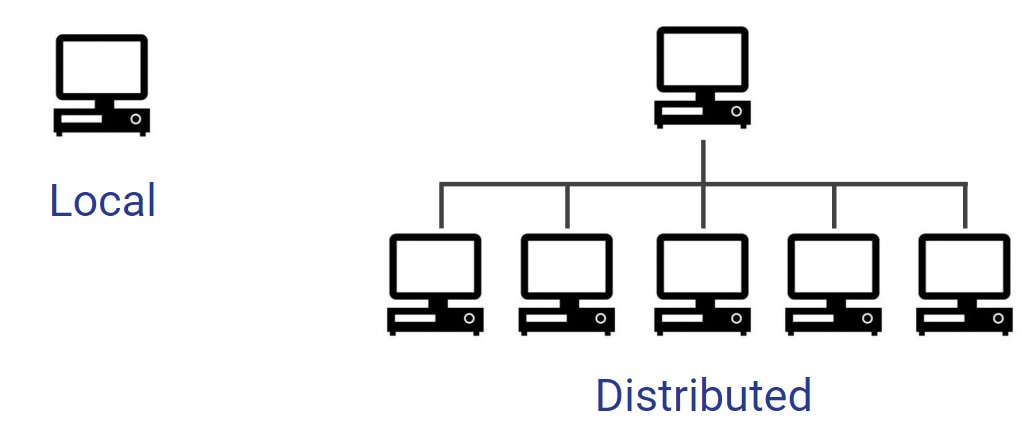
اللوكال سيستم هو المعتادين عليه والدارج ومكون من جهاز واحد ونظام واحد يتشاركو نفس الرام و والتخزين والموارد الخ..
طيب قبل كل شي خلونا نعرف ايش يعني :
Local Systems & Distributed Systems
اللوكال سيستم هو المعتادين عليه والدارج ومكون من جهاز واحد ونظام واحد يتشاركو نفس الرام و والتخزين والموارد الخ..
4
الانظمة الموزعة عبارة عن جهاز اساسي يطلق عليه الـ node الرئيسية بحيث يقوم بتوزيع البيانات الي على الاجهزة الباقية المتصلة فيه او الـSlave nodes.
الانظمة الموزعة عبارة عن جهاز اساسي يطلق عليه الـ node الرئيسية بحيث يقوم بتوزيع البيانات الي على الاجهزة الباقية المتصلة فيه او الـSlave nodes.
5
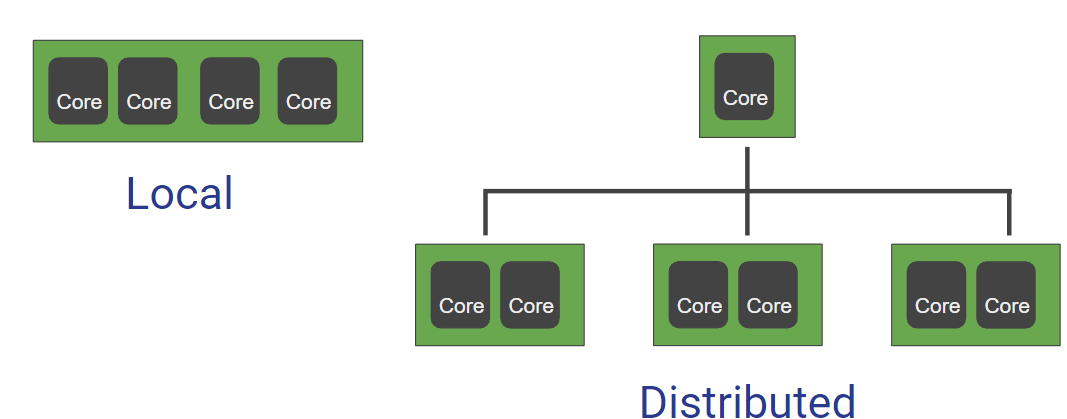
الفرق بينهم انه في الـ Local راح تكون محصور بعدد معين من الانوية والقدرات والموارد بينما في الـ Distributed راح توزع القدرات على اجهزة متعددة ولكن اقل كفاءة وبهذا العدد الاكبر راح تنتهي بقدرات اقوى حاسوبيا من جهاز او نظام واحد.
الفرق بينهم انه في الـ Local راح تكون محصور بعدد معين من الانوية والقدرات والموارد بينما في الـ Distributed راح توزع القدرات على اجهزة متعددة ولكن اقل كفاءة وبهذا العدد الاكبر راح تنتهي بقدرات اقوى حاسوبيا من جهاز او نظام واحد.
6
ويميزها ايضا انو ممكن يزيد عدد المشينز حسب الاحتياج بدون ما يحتاج زيادة سعة المعالج،، وهي نفس الفكرة الي يسويها سبارك.
-
ولو اتكلمنا عن الـ Fault tolerance في الـ Distributed راح يكون افضل بمراحل،، في حال تعرض مشين واحد لتلف كل النتتورك لازالت قادرة على العمل بدون مشاكل.
ويميزها ايضا انو ممكن يزيد عدد المشينز حسب الاحتياج بدون ما يحتاج زيادة سعة المعالج،، وهي نفس الفكرة الي يسويها سبارك.
-
ولو اتكلمنا عن الـ Fault tolerance في الـ Distributed راح يكون افضل بمراحل،، في حال تعرض مشين واحد لتلف كل النتتورك لازالت قادرة على العمل بدون مشاكل.
7
طيب نتكلم عن الاركتكشر المتعارف عليه باستخدام هدوب
ايش هدوب؟
-
هدوب هي طريقة لتوزيع الملفات الكبيرة على اجهزة متعددة باستخدام HDFS والي يسمح لليوزر بالعمل على داتا سيتس كبيرة وايضا من المزايا الي يقدمها الـ HFDS انو يسوي نسخ من الداتا Blocks حتى يكون الـFault tolerance اكبر
طيب نتكلم عن الاركتكشر المتعارف عليه باستخدام هدوب
ايش هدوب؟
-
هدوب هي طريقة لتوزيع الملفات الكبيرة على اجهزة متعددة باستخدام HDFS والي يسمح لليوزر بالعمل على داتا سيتس كبيرة وايضا من المزايا الي يقدمها الـ HFDS انو يسوي نسخ من الداتا Blocks حتى يكون الـFault tolerance اكبر

8
بحيث لو كان فيه فقد لنسخة معينة راح يكون فيه لها اكثر بديل ومتوزعة في اكثر من مكان"زي النسخ الاحتياطي".
-
ويستخدم HFDS الـMap Reduce وهو الي يسمح باجراء العمليات الحسابية على هاذي البيانات الموزعة.
-
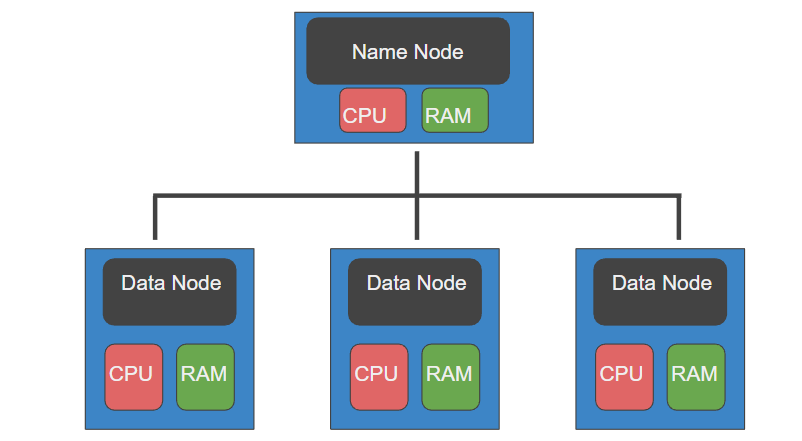
وعشان توضح فكرة HFDS راح يكون فيه Master node لها قدراتها المعالجية الخاصة.
بحيث لو كان فيه فقد لنسخة معينة راح يكون فيه لها اكثر بديل ومتوزعة في اكثر من مكان"زي النسخ الاحتياطي".
-
ويستخدم HFDS الـMap Reduce وهو الي يسمح باجراء العمليات الحسابية على هاذي البيانات الموزعة.
-
وعشان توضح فكرة HFDS راح يكون فيه Master node لها قدراتها المعالجية الخاصة.
9
ويقوم المعالج فيها بتوزيع البيانات و العمليات على السليف نودز.
بحيث يقسم HFDS البيانات الى Blocks حجمها 128 ميقا بشكل افتراضي وكل بلوك يتم نسخه 3 مرات وتتوزع،، واما MAP REDUCE يعتبر طريقة لتوزيع العمليات الحسابية على النودز.
ويقوم المعالج فيها بتوزيع البيانات و العمليات على السليف نودز.
بحيث يقسم HFDS البيانات الى Blocks حجمها 128 ميقا بشكل افتراضي وكل بلوك يتم نسخه 3 مرات وتتوزع،، واما MAP REDUCE يعتبر طريقة لتوزيع العمليات الحسابية على النودز.
10
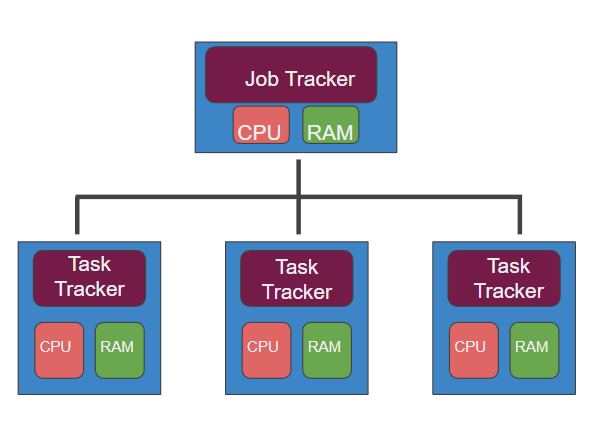
وبعد كدا الجوب تراكر يرسل التاسك ويتنفذ على التاسك تراكر وبعد كدا التاسك تراكر يقوم يتعيين الموارد اللازمة ويراقب سير الامر حتى ينتهي.
-
وبعد كدا الجوب تراكر يرسل التاسك ويتنفذ على التاسك تراكر وبعد كدا التاسك تراكر يقوم يتعيين الموارد اللازمة ويراقب سير الامر حتى ينتهي.
-
11
طيب خلونا الان نتكلم عن سبارك وايش هو سبارك.
-
باختصار سبارك هو من احدث التقنيات في التعامل مع البيانات الضخمة ويعتبر مشروع مفتوح المصدر على اباتشي.
-
تم اطلاقه في 2013 واشتهر بسبب سهولة الاستخدام واداءه العالي.
طيب خلونا الان نتكلم عن سبارك وايش هو سبارك.
-
باختصار سبارك هو من احدث التقنيات في التعامل مع البيانات الضخمة ويعتبر مشروع مفتوح المصدر على اباتشي.
-
تم اطلاقه في 2013 واشتهر بسبب سهولة الاستخدام واداءه العالي.
12
ممكن تتخيل سبارك على انو بديل لـMap Reduce قادر على انو يتعامل مع البيانات بشتى صيغ تخزينها زي :-
-Cassandra
-AWS S3
-HDFS
وغيرها الكثير.
ممكن تتخيل سبارك على انو بديل لـMap Reduce قادر على انو يتعامل مع البيانات بشتى صيغ تخزينها زي :-
-Cassandra
-AWS S3
-HDFS
وغيرها الكثير.
13
الفكرة الرئيسية لعمل سبارك هي
Resilient Distributed Dataset RDD
والـRDD يحتوى على 4 خصائص:-
-Distributed Collection of Data
-Fault-tolerant
-Parallel operation - partitioned
-Ability to use many data sources
الفكرة الرئيسية لعمل سبارك هي
Resilient Distributed Dataset RDD
والـRDD يحتوى على 4 خصائص:-
-Distributed Collection of Data
-Fault-tolerant
-Parallel operation - partitioned
-Ability to use many data sources
14
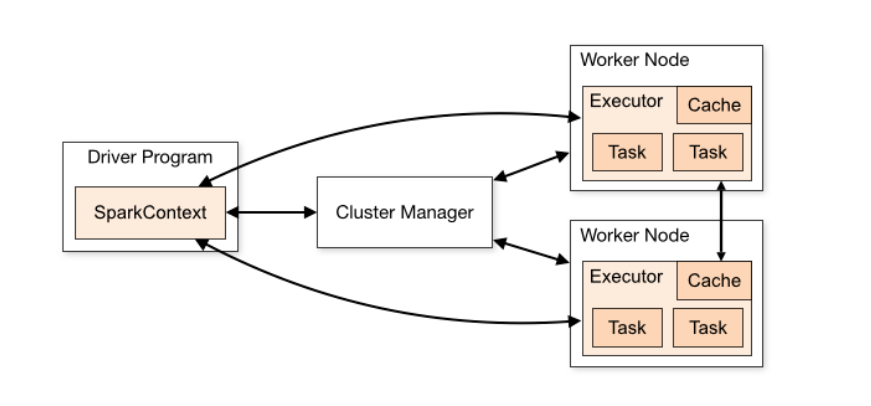
راح يكون Spark مشابه لـMap Reduce فريمورك الي فيه درايفر بروقرام وسبارك سيشن او كلستر مانجر "في حال كنا نستخدم اصدار 2.0" بالاضافة لمانجر وسليف نودز.
راح يكون Spark مشابه لـMap Reduce فريمورك الي فيه درايفر بروقرام وسبارك سيشن او كلستر مانجر "في حال كنا نستخدم اصدار 2.0" بالاضافة لمانجر وسليف نودز.
15
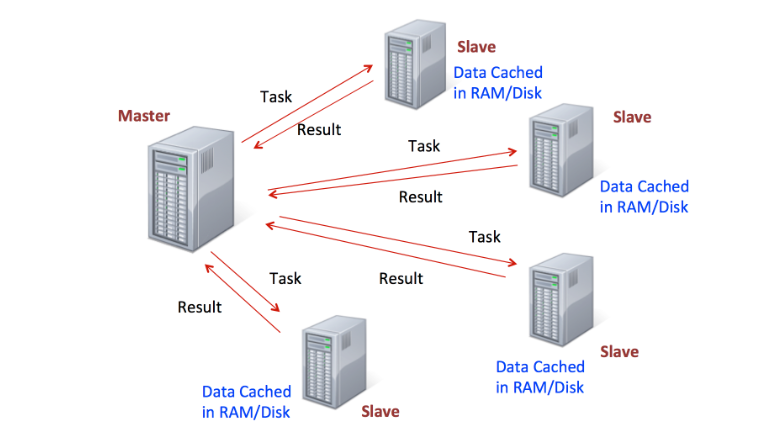
طيب في الـReal Life كيف راح يكون الـ Architecture؟
سيرفرات موزعة ومربوطين بماستر نود الي ترسل التاسكات والسليفز يرجعو الـResults.
-
وتنقسم العمليات في سبارك الى Transfer او Actions
ونقدر نوصفها بانو النقل هو خطة تتبعها والاكشنز تنفذ الخطوات الموجودة في الخطة وترجع لك نتيجة.
طيب في الـReal Life كيف راح يكون الـ Architecture؟
سيرفرات موزعة ومربوطين بماستر نود الي ترسل التاسكات والسليفز يرجعو الـResults.
-
وتنقسم العمليات في سبارك الى Transfer او Actions
ونقدر نوصفها بانو النقل هو خطة تتبعها والاكشنز تنفذ الخطوات الموجودة في الخطة وترجع لك نتيجة.
جاري تحميل الاقتراحات...