

We now finally have the thing I've always wanted: an analysis of the best vision models for finetuning.
In joint work with @capetorch we tried nearly 100 models on two very different datasets across various hyperparams.
Here's the top 15 on the IIT-Pet dataset: 1/🧵
In joint work with @capetorch we tried nearly 100 models on two very different datasets across various hyperparams.
Here's the top 15 on the IIT-Pet dataset: 1/🧵
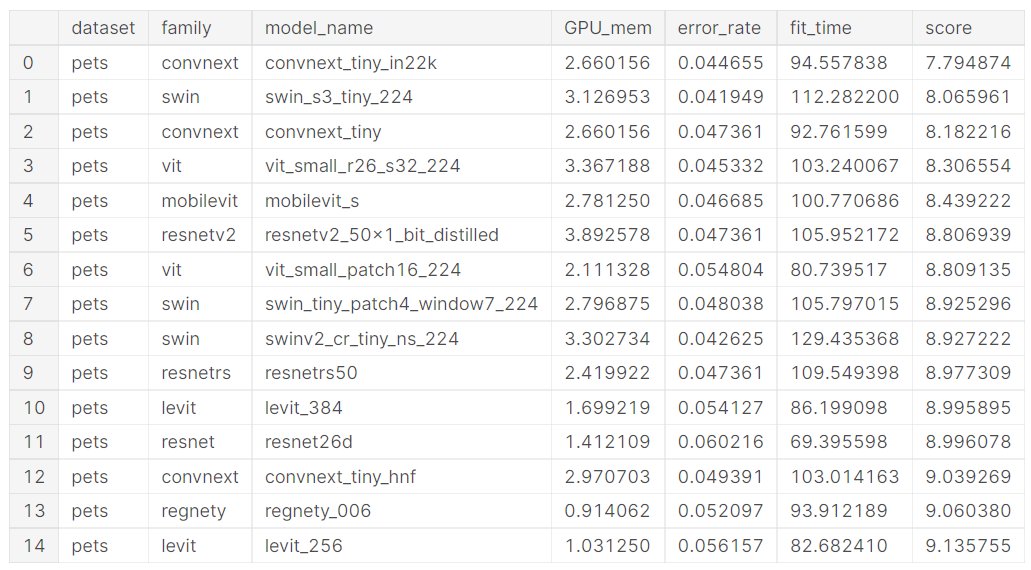
IIT-Pet is a larger dataset, containing images (pet breeds) very similar to the dataset the model was trained on (imagenet).
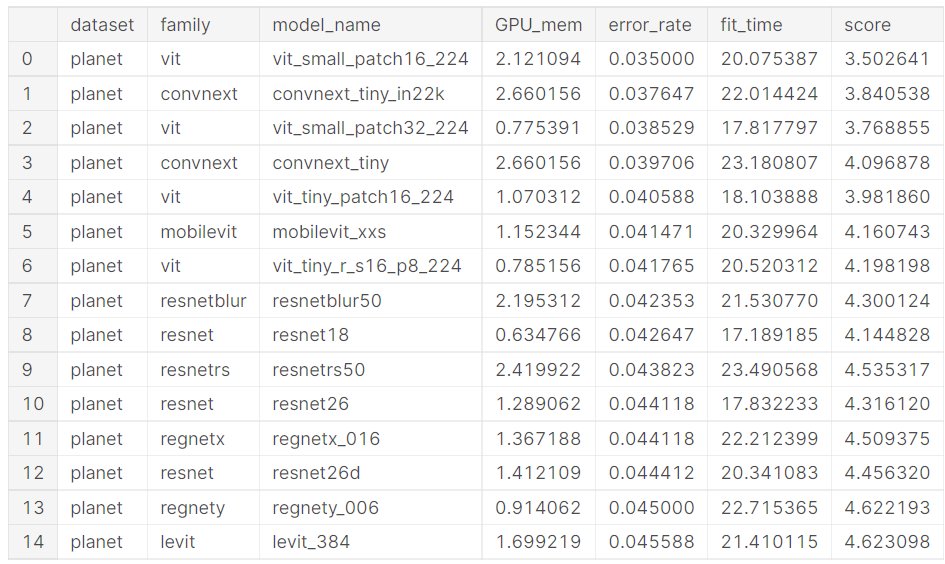
Here's the top 15 on Planet, which is a smaller dataset containing satellite imagery, which is unlike anything in imagenet:
Here's the top 15 on Planet, which is a smaller dataset containing satellite imagery, which is unlike anything in imagenet:
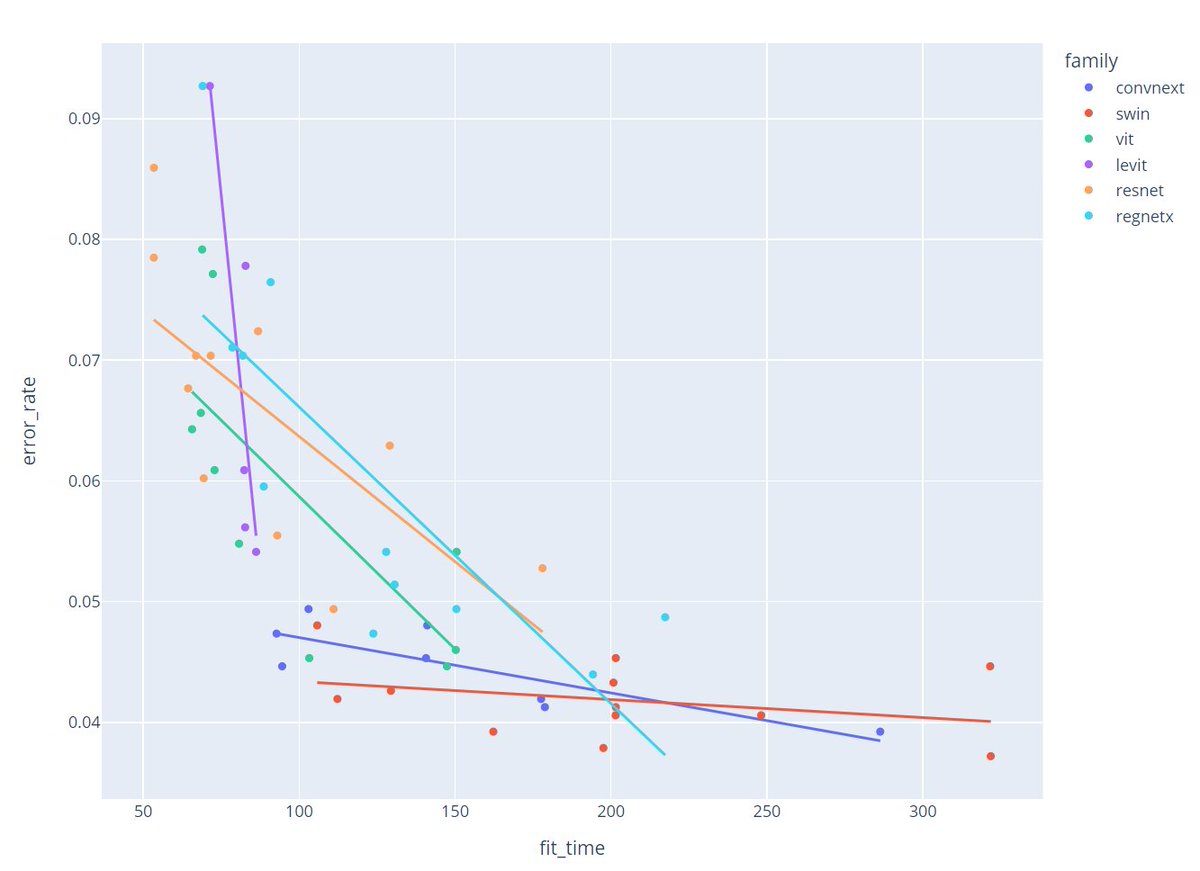
Here's the relationship between speed and accuracy on IIT-Pet. As you can see, using bigger/slower models pays off with better accuracy, but there are diminishing returns
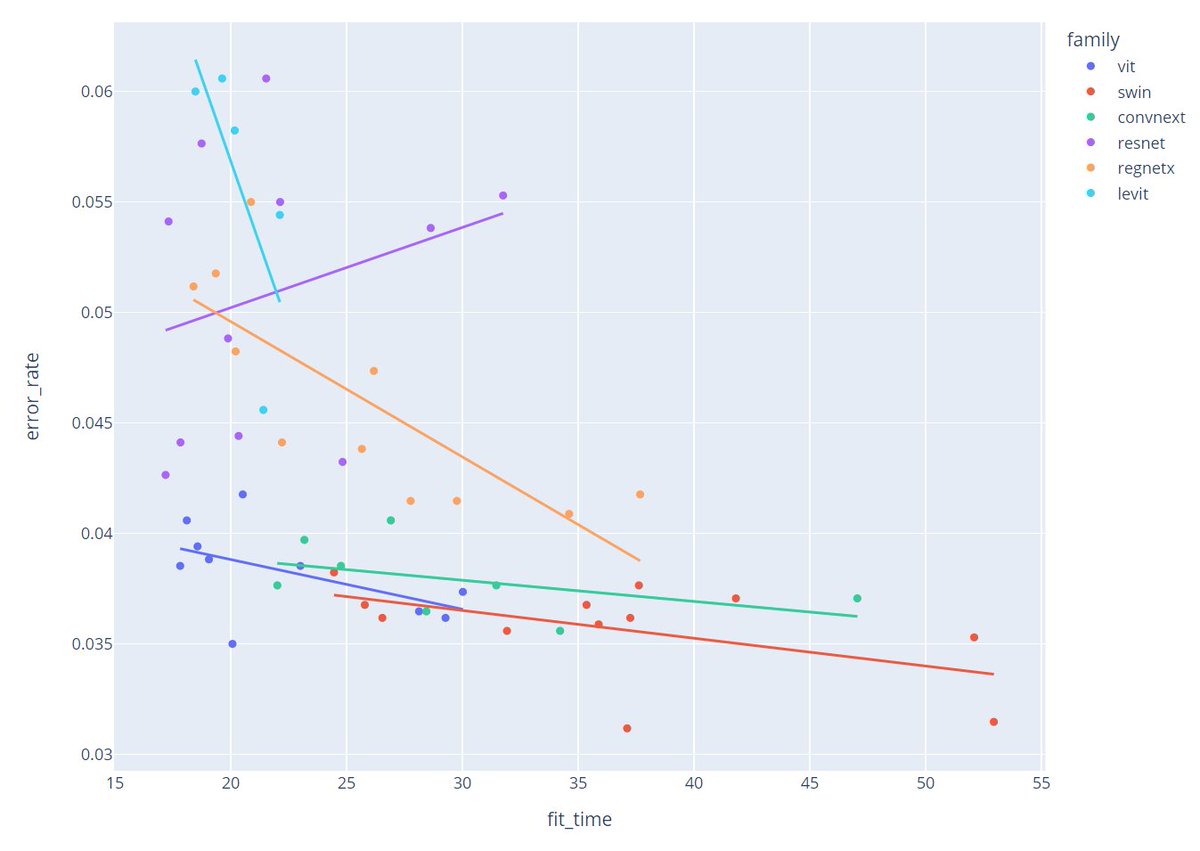
However the relationship is much less clear on Planet. This suggests that if you're working with a small-ish dataset that's not similar to your pretrained model's dataset, you may want to focus on smaller/faster architectures.
I've put together a writeup of the whole approach, and we've made the results and code publicly available to anyone who wants to dig in themselves:
kaggle.com
kaggle.com
جاري تحميل الاقتراحات...