
التكنولوجيا
DevOps
الحوسبة السحابية
تطوير البرمجيات
هندسة البرمجيات
أنظمة التوزيع
هندسة الفوضى
هندسة موثوقية المواقع

هيحصل إيه لو دخلنا قرد في غرفة السيرفرات وسبناه يلعب؟ يفصل الكهربا عن السيرفرات، يدوس على الزراير، يقطع الأسلاك، ويعمل كل حاجة؟ هي دي هندسة الفوضى أو Chaos Engineering.
في السنوات الأخيرة ال Software Systems بقت أكثر تعقيدأ ومرت ب 3 مراحل مهمة للتعامل مع تعقيداتها:
في السنوات الأخيرة ال Software Systems بقت أكثر تعقيدأ ومرت ب 3 مراحل مهمة للتعامل مع تعقيداتها:
أولا: ال DevOps اللي زود التفاعل بين ال Developers وال Operations وده رفع الإنتاجية Productivity وسرع ال Delivery.
ثانياً: ال Site Reliability Engineering والفضل فيها ل Google. عن طريق ال SRE قدرنا نزود ال Reliability وال Availability وتحديداً في ال Distributed Systems.
ثانياً: ال Site Reliability Engineering والفضل فيها ل Google. عن طريق ال SRE قدرنا نزود ال Reliability وال Availability وتحديداً في ال Distributed Systems.
ثالثاً وأحدث حاجه: ال Chaos Engineering والفضل فيها ل Netflix. وده محور موضوعنا.
الفكرة بدأت داخلياً في نتفليكس في 2011 إثناء انتقالهم لل Cloud. كانوا محتاجين طريقة يتأكدوا بيها من ال Resilience لما تحصل مشاكل غير متوقعة في ال Production. فكرة ال Resilience هي في قدرة
الفكرة بدأت داخلياً في نتفليكس في 2011 إثناء انتقالهم لل Cloud. كانوا محتاجين طريقة يتأكدوا بيها من ال Resilience لما تحصل مشاكل غير متوقعة في ال Production. فكرة ال Resilience هي في قدرة
السيستم على التعافي بسهولة لما تحصل ليه مشكلة. المشاكل أمر حتمي. التحدي الفعلي مش بس في منعها، وإنما في التعافي السريع منها. لما سيستم يقع يكون عندك بدائل. لما حاجة متشتغلش مع عميل، مفيش مشكلة بس في ثواني تكون اتصلحت. شفت فيديو لخبير كان بيتكلم عن مستوى استجابة سريع
يخلي العميل يشك في جهازه أو الانترنت عنده. لإن الثانية اللي عمل فيها ريفريش كنا حلينا المشكلة وهو محسش إننا وقعنا.
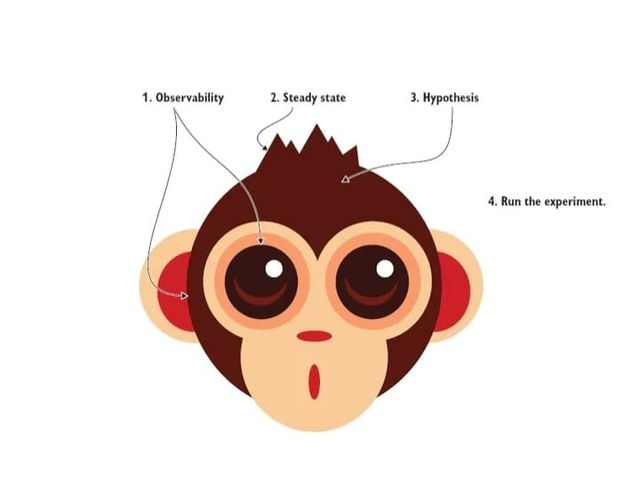
ايه خطوات ال Chaos Engineering؟
- إتأكد أن عندك Observability جيدة. قادر تراقب السيستم وتشوف كل ال metrics بفعالية ودقة.
ايه خطوات ال Chaos Engineering؟
- إتأكد أن عندك Observability جيدة. قادر تراقب السيستم وتشوف كل ال metrics بفعالية ودقة.
- تحديد ال steady-state behavior ودي الحالة المثالية اللي حابب السيستم يكون عليها.
- بناء ال Hypothesis. بمعنى لو شيء معين حصل، النتيجة المتوقعة كذا. مثال: لو ربع سيرفراتنا وقعت، هنكون قادرين نخدم 99% من عملائنا بمتوسط استجابة 250 ميلي ثانية. ده افتراض مبني على SLA, SLI, SLO
- بناء ال Hypothesis. بمعنى لو شيء معين حصل، النتيجة المتوقعة كذا. مثال: لو ربع سيرفراتنا وقعت، هنكون قادرين نخدم 99% من عملائنا بمتوسط استجابة 250 ميلي ثانية. ده افتراض مبني على SLA, SLI, SLO
ودي مفاهيم من ال SRE . في الخطوة دي هنعمل قائمة كبيرة من الافتراضات عشان نجربها في الخظوة التالية.
- تنفيذ ال Experiment. هنختبر كل افتراض. لو الافتراض اتحقق، جميل .. كده ازدادت موثوقيتنا في النظام. لو الافتراض متحققش، برضو جميل .. كده عرفنا إن فيه مشكلة وهنشتغل عليها عشان متحصلش
- تنفيذ ال Experiment. هنختبر كل افتراض. لو الافتراض اتحقق، جميل .. كده ازدادت موثوقيتنا في النظام. لو الافتراض متحققش، برضو جميل .. كده عرفنا إن فيه مشكلة وهنشتغل عليها عشان متحصلش
نرجع للقرد. في 2011 نتفليكس عملت أداة سمتها Chaos Monkey ودي شغالة 24 ساعة وبعشوائية تقفل السيرفرات وتعمل مشاكل في ال Infrastructure عشان تتأكد من ال Resilience. خد بالك إن الاختبار هنا بيتم على Live Production Environment وهو ده الفرق الجوهري بينها وبين الاختبارات التقليدية.
وعشان عندي Observability فانا بتعلم من القرد وهو شغال. لحسن الحظ إن السوفتوير ده مفتوح المصدر. لكن ده مش السوفتوير الوحيد. وكل الشركات الكبرى عندنا ميكانيزم شبيهة زي Facebook Storm مثلا.
إضافات على الهامش:
- في الهندسة التقليدية (مباني وماكينات، الخ) فيه مفهوم
إضافات على الهامش:
- في الهندسة التقليدية (مباني وماكينات، الخ) فيه مفهوم
Resilience Engineering وده بيقول ببساطة إن ال failure مش malfunction وإنما استجابة طبيعية وAdaptation من السيستم لما بيقابل العالم الحقيقي. المفهوم أقدم بكتير من صناعة السوفتوير.
- من أهم فوائد ال Chaos Engineering تحديد التكلفة. تكلفة الاستعداد للتعامل مع المشكلة وتكلفة التعافي من المشكلة، والاتنين مهمين جداً للشركات في استراتيجيات تسعير خدماتهم.
جاري تحميل الاقتراحات...