

ما هي قواعد البيانات التي يستخدمها علماء تحليل البيانات؟
ما المعايير التي تختار من خلالها قاعدة البيانات أثناء عملك كمحلل بيانات؟
ما معني Hadoop , Spark , Sql , Nosql ؟
كيف يتم تخزين البيانات ومعالجتها ؟
ما معني إدارة قواعد البيانات ؟
ثريد مميز حول قواعد البيانات وإدارتها👇
ما المعايير التي تختار من خلالها قاعدة البيانات أثناء عملك كمحلل بيانات؟
ما معني Hadoop , Spark , Sql , Nosql ؟
كيف يتم تخزين البيانات ومعالجتها ؟
ما معني إدارة قواعد البيانات ؟
ثريد مميز حول قواعد البيانات وإدارتها👇

لإتقان علم البيانات بالكامل ، يجب أن تفهم إدارة البيانات جنبًا إلى جنب مع جميع أو بعض مهارات التعلم الآلي هذه الخطوات بمثابة دليل للخيارات الموسعة لتخزين البيانات وحلول البنية التحتية
لكي تكون عالم بيانات حقيقيًا Data Scientist ، عليك أن تتقن كل خطوة في عملية علم البيانات - على طول الطريق من تخزين بياناتك إلى وضع منتجك النهائي حتي بناء ( نموذجًا تنبئيًا) باستخدام خوارزميات ML لكن الجزء الأكبر من التدريب على علوم البيانات يركز على تقنيات التعلم الآلي / العميق
؛ غالبًا ما يتم التعامل مع معرفة إدارة البيانات على أنها ليست مهمة عادةً ما يتعلم طلاب في علوم البيانات مهارات مثل النمذجة وتنظيف النصوص وتخزينها على أجهزة الكمبيوتر المحمول الخاصة بهم ، متجاهلين كيفية صنع قواعد البيانات وطرق التعامل معها
غالبًا لا يدرك الطلاب أنه في إعدادات عمليات تحليل البيانات ، فإن الحصول على البيانات الأولية من مصادر مختلفة لتكون جاهزة للنمذجة عادةً ما يشغل 80٪ من العمل والتحليل ونظرًا لأن مشروعات المؤسسات عادةً ما تتضمن قدرًا هائلاً من البيانات التي لا تكون أجهزتها المحلية مجهزة للتعامل معه
فإن عملية النمذجة بأكملها غالبًا ما تتم في السحابة مثل خدمات التخزن السحابية التي تقدمها شركات مثل Amazon Cloud ، مع استضافة معظم التطبيقات وقواعد البيانات على الخوادم في مراكز البيانات في أماكن أخرى حتى بعد حصول الطالب على وظيفة كعالم بيانات ،
غالبًا ما تصبح إدارة البيانات شيئًا يهتم به فريق هندسة بيانات منفصل نتيجة لذلك ، يعرف الكثير من علماء البيانات القليل جدًا عن تخزين البيانات والبنية التحتية ، غالبًا على حساب قدرتهم على اتخاذ القرارات الصحيحة في وظائفهم الهدف
من هذه المقالة هو توفير خارطة طريق لما يجب أن يعرفه عالم البيانات, وإدارة البيانات - وأنواع قواعد البيانات ، أين وكيف يتم تخزين البيانات ومعالجتها ، إلى الخيارات التجارية الحالية - وبالتالي يمكن أن تتعمق أو على الأقل تتعلم ما يكفي للتعامل مع قواعد البيانات
ظهور البيانات غير المهيكلة وأدوات البيانات الضخمة
قصة علم البيانات هي في الحقيقة قصة تخزين البيانات في عصر ما قبل العصر الرقمي ، تم تخزين البيانات في رؤوسنا أو على ألواح طينية أو على الورق ، مما جعل تجميع البيانات وتحليلها يستغرق وقتًا طويلاً للغاية في عام 1956
قصة علم البيانات هي في الحقيقة قصة تخزين البيانات في عصر ما قبل العصر الرقمي ، تم تخزين البيانات في رؤوسنا أو على ألواح طينية أو على الورق ، مما جعل تجميع البيانات وتحليلها يستغرق وقتًا طويلاً للغاية في عام 1956

قدمت شركة IBM أول كمبيوتر تجاري به محرك أقراص ثابت مغناطيسي 305 RAMAC تطلبت الوحدة بأكملها 30 قدمًا × 50 قدمًا من المساحة ، ووزنها أكثر من طن ، ولمقابل 3200 دولار شهريًا ، يمكن للشركات استئجار الوحدة لتخزين ما يصل إلى 5 ميغا بايت من البيانات
في 60 عامًا منذ أن انخفضت أسعار كل جيجابايت في DRAM من 2.64 مليار دولار في عام 1965 إلى 4.9 دولار في عام 2017 بالإضافة إلى كونها أرخص بكثير ، أصبح تخزين البيانات أيضًا أكثر كثافة / أصغر في الحجم تم تخزين مائة بت لكل بوصة مربعة في 305 RAMAC
هذا المزيج من التكلفة والحجم المنخفضين بشكل كبير في تخزين البيانات هو ما يجعل تحليلات البيانات الضخمة اليوم ممكنة بفضل تكاليف التخزين المنخفضة للغاية ، أصبح بناء البنية التحتية لعلوم البيانات لجمع الأفكار من كمية هائلة من البيانات واستخراجها منهجًا مربحًا للشركات
ومع وفرة أجهزة إنترنت الأشياء التي تنشئ وتنقل بيانات المستخدمين باستمرار تقوم الشركات بجمع البيانات حول عدد متزايد من الأنشطة ، مما يخلق قدرًا هائلاً من أصول المعلومات عالية الحجم وعالية السرعة والمتنوعة (أو "الثلاثة مقابل البيانات الضخمة").
تولد معظم هذه الأنشطة (مثل رسائل البريد الإلكتروني ومقاطع الفيديو والصوت ورسائل الدردشة ومنشورات وسائل التواصل الاجتماعي) بيانات غير منظمة ، والتي تمثل ما يقرب من 80٪ من إجمالي بيانات المؤسسة اليوم وتنمو أسرع بمرتين من البيانات المنظمة في العقد الماضي.
أدى هذا النمو الهائل في البيانات إلى تغيير طريقة تخزين البيانات وتحليلها بشكل كبير ، حيث لم تكن الأدوات والأساليب التقليدية مجهزة للتعامل مع البيانات الضخمة تم تطوير تقنيات جديدة مع القدرة على التعامل مع الحجم المتزايد باستمرار للبيانات وتنوعها
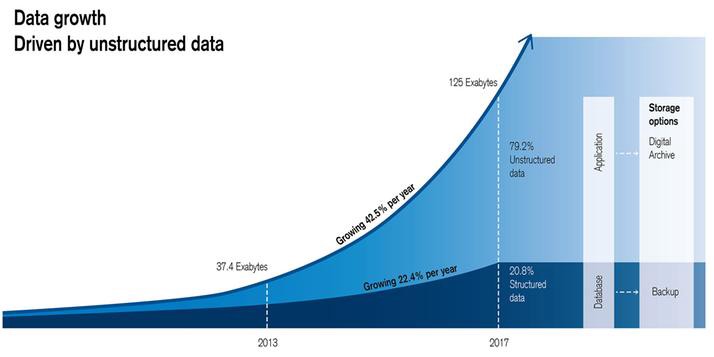
وبسرعة أكبر وبتكلفة أقل هذه الأدوات الجديدة لها أيضًا تأثيرات عميقة على كيفية قيام علماء البيانات بعملهم - مما يسمح لهم باستثمار حجم البيانات الهائل من خلال إجراء التحليلات وبناء تطبيقات جديدة لم تكن ممكنة من قبل
فيما يلي أهم ابتكارات إدارة البيانات الضخمة التي نعتقد أن كل عالم بيانات يجب أن يعرفها.
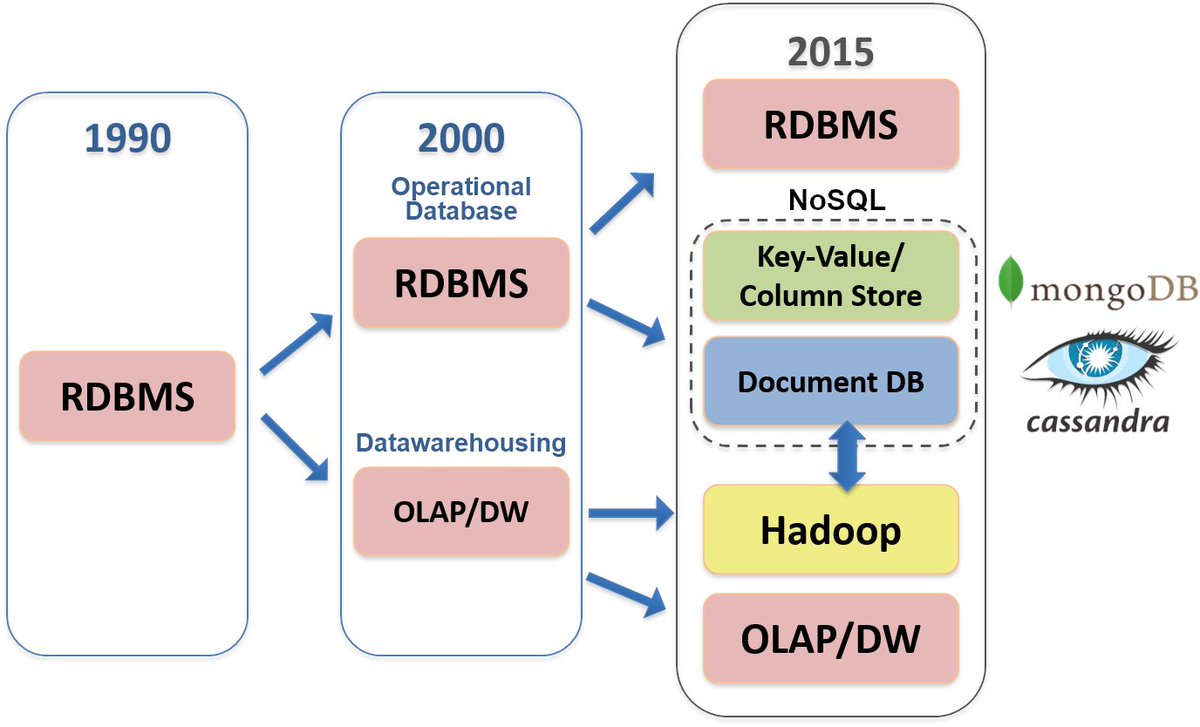
قواعد البيانات العلائقية و NoSQL
ظهرت أنظمة إدارة قواعد البيانات العلائقية (RDBMS) في السبعينيات لتخزين البيانات كجداول بها صفوف وأعمدة ، باستخدام عبارات لغة الاستعلام الهيكلية (SQL) للاستعلام عن قاعدة البيانات والحفاظ عليها
ظهرت أنظمة إدارة قواعد البيانات العلائقية (RDBMS) في السبعينيات لتخزين البيانات كجداول بها صفوف وأعمدة ، باستخدام عبارات لغة الاستعلام الهيكلية (SQL) للاستعلام عن قاعدة البيانات والحفاظ عليها
قاعدة البيانات العلائقية هي في الأساس مجموعة من الجداول ، ولكل منها مخطط يحدد بشكل صارم سمات وأنواع البيانات التي يخزنها ، بالإضافة إلى المفاتيح التي تحدد أعمدة أو صفوفًا معينة لتسهيل الوصول كان مشهد RDBMS محكومًا من قبل Oracle و IBM ، ولكن اليوم العديد من الخيارات مفتوحة المصدر
، مثل MySQL و SQLite و PostgreSQL تحظى بشعبية كبيرة.
وجدت قواعد البيانات العلائقية مكانًا لها في عالم الأعمال بسبب بعض الخصائص الجذابة للغاية تكامل البيانات أمر بالغ الأهمية ، في قواعد البيانات العلائقية يلبي RDBMS جميع المتطلبات اللازمة (أو المتوافقة مع ACID)
وجدت قواعد البيانات العلائقية مكانًا لها في عالم الأعمال بسبب بعض الخصائص الجذابة للغاية تكامل البيانات أمر بالغ الأهمية ، في قواعد البيانات العلائقية يلبي RDBMS جميع المتطلبات اللازمة (أو المتوافقة مع ACID)
من خلال فرض عدد من القيود لضمان موثوقية البيانات المخزنة ودقتها ، مما يجعلها مثالية لتتبع وتخزين أشياء مثل أرقام الحسابات والأوامر ، والمدفوعات لكن هذه القيود تأتي مع مقايضات مكلفة بسبب قيود المخطط والنوع
، فإن RDBMS رهيب في تخزين البيانات المهيكلة أو شبه المنظمة مما يجعل المخطط أيضًا RDBMS أكثر تكلفة في الإعداد والصيانة والنمو ويتطلب إعداد نظام RDBMS أن يكون لدى المستخدمين حالات استخدام محددة مسبقًا ؛
بحلول منتصف العقد الأول من القرن الحادي والعشرين ، لم يعد نظام RDBMS الحالي قادرًا على التعامل مع الاحتياجات المتغيرة والنمو الهائل لعدد قليل من الشركات الناجحة جدًا عبر الإنترنت
وتم تطوير العديد من قواعد البيانات غير العلائقية (أو NoSQL) نتيجة لذلك (إليك قصة عن كيفية تعامل Facebook مع قيود MySQL عندما بدأ حجم البيانات في النمو).
بدون أي حلول في ذلك الوقت ابتكرت هذه الشركات عبر الإنترنت أساليب وأدوات جديدة للتعامل مع الكم الهائل من البيانات غير المنظمة التي جمعوها أنشأت Google GFS و MapReduce و BigTable ؛أنشأت أمازون DynamoDB ؛أنشأت ياهو برنامج Hadoop ؛ أنشأ Facebook Cassandra و Hive ،أنشأ لينكد إن Kafka
قواعد بيانات NoSQL
غير مخططة وتوفر المرونة اللازمة لتخزين ومعالجة كميات كبيرة من البيانات غير المهيكلة وشبه المنظمة لا يحتاج المستخدمون إلى معرفة أنواع البيانات التي سيتم تخزينها أثناء الإعداد ، ويمكن للنظام استيعاب التغييرات في أنواع البيانات والمخطط.
غير مخططة وتوفر المرونة اللازمة لتخزين ومعالجة كميات كبيرة من البيانات غير المهيكلة وشبه المنظمة لا يحتاج المستخدمون إلى معرفة أنواع البيانات التي سيتم تخزينها أثناء الإعداد ، ويمكن للنظام استيعاب التغييرات في أنواع البيانات والمخطط.
صُممت قواعد بيانات NoSQL لتوزيع البيانات عبر عقد مختلفة ، وهي عمومًا أكثر قابلية للتوسع أفقيًا وتتسامح مع الأخطاء ومع ذلك ، فإن مزايا الأداء هذه تأتي أيضًا مع تكلفة - قواعد بيانات NoSQL ليست متوافقة مع ACID
يوجد الآن عدة فئات مختلفة من NoSQL ، كل منها يخدم بعض الأغراض المحددة تقوم القواعد ذات القيمة الأساسية ، مثل Redis و DynamoDB و Cosmos DB ، بتخزين أزواج المفتاح والقيمة فقط وتوفر الوظائف الأساسية لاسترداد القيمة المرتبطة
تقوم قواعد المستندات ، مثل MongoDB و Couchbase ، بتخزين البيانات بتنسيق XML أو JSON ، مع اسم المستند كمفتاح ومحتويات المستند كقيمة يمكن أن تحتوي المستندات على العديد من أنواع القيم المختلفة ويمكن أن تكون متداخلة ، مما يجعلها مناسبة بشكل خاص لإدارة البيانات شبه المنظمة
تعد MongoDB حاليًا قاعدة بيانات NoSQL الأكثر شيوعًا وقد قدمت قيمًا جوهرية لبعض الشركات التي كانت تكافح للتعامل مع بياناتها غير المهيكلة باستخدام نهج RDBMS التقليدي فيما يلي مثالان على الصناعة:
بعد أن قضت شركة MetLife سنوات في محاولة بناء قاعدة بيانات مركزية للعملاء على نظام RDBMS يمكنه التعامل مع جميع منتجات التأمين الخاصة بها قام شخص ما في هاكاثون ببناء MongoDB في غضون ساعات والذي بدأ الإنتاج في90 يومًا Kafka هي شركة أبحاث السوق تجمع 5 جيجا بايت من البيانات في الساعة
مستودع البيانات Data Warehouse & Data Lakes
مع استمرار نمو مصادر البيانات ، أصبح إجراء تحليلات البيانات باستخدام قواعد بيانات متعددة غير فعال ومكلف ظهر حل واحد يسمى Data Warehouse في الثمانينيات
مع استمرار نمو مصادر البيانات ، أصبح إجراء تحليلات البيانات باستخدام قواعد بيانات متعددة غير فعال ومكلف ظهر حل واحد يسمى Data Warehouse في الثمانينيات
، والذي يعمل على مركزية بيانات المؤسسة من جميع قواعد بياناتها يدعم Data Warehouse تدفق البيانات من الأنظمة التشغيلية إلى أنظمة التحليلات / اتخاذ القرار من خلال إنشاء مستودع واحد للبيانات من مصادر مختلفة (داخلية وخارجية) في معظم الحالات
يعد مستودع البيانات قاعدة بيانات علائقية تخزن البيانات التي تمت معالجتها والتي تم تحسينها لجمع رؤى الأعمال يقوم بجمع البيانات بهيكل ومخطط محدد مسبقًا قادم من أنظمة المعاملات وتطبيقات الأعمال ، وعادة ما تستخدم البيانات لإعداد التقارير التشغيلية والتحليل.
ولكن نظرًا لأن البيانات التي يتم إدخالها إلى مستودعات البيانات تحتاج إلى المعالجة قبل تخزينها - نظرًا للكم الهائل من البيانات غير المنظمة اليوم ، فقد يستغرق ذلك وقتًا وموارد كبيرة استجابةً لذلك ، بدأت الشركات في صيانة Data Lakes في 2010 ،
والتي تخزن جميع البيانات المهيكلة وغير المهيكلة للمؤسسة على أي نطاق ، تقوم Data Lakes بتخزين البيانات الأولية ، ويمكن إعدادها دون الحاجة إلى تحديد هيكل البيانات والمخطط أولاً
تسمح Data Lakes للمستخدمين بتشغيل التحليلات دون الحاجة إلى نقل البيانات إلى نظام تحليلات منفصل ، مما يمكّن الشركات من اكتساب رؤى من مصادر جديدة للبيانات لم تكن متاحة للتحليل من قبل ،
على سبيل المثال عن طريق بناء نماذج التعلم الآلي باستخدام البيانات من ملفات السجل وجعل جميع بيانات المؤسسة متاحة بسهولة للتحليل ، يمكن لعلماء البيانات الإجابة على مجموعة جديدة من أسئلة العمل ، أو معالجة الأسئلة القديمة ببيانات جديدة.
يتمثل أحد التحديات الشائعة في بنية Data Lake في أنه بدون جودة البيانات المناسبة وإطار الحوكمة ، عندما تتدفق تيرابايت من البيانات المهيكلة وغير المهيكلة إلى بحيرات البيانات ، غالبًا ما يكون من الصعب للغاية فرز محتواها يمكن أن تتحول بحيرات البيانات إلى مستنقعات بيانات
حيث تصبح البيانات المخزنة فوضوية للغاية بحيث لا يمكن استخدامها تدعو العديد من المنظمات الآن إلى مزيد من ممارسات إدارة البيانات وإدارة البيانات الوصفية لمنع تكون مستنقعات البيانات.
المعالجة الموزعة والمتوازية: Hadoop و Spark و MPP
في حين نمت احتياجات التخزين والحوسبة بسرعة فائقة في العقود العديدة الماضية ، لم تتقدم الأجهزة التقليدية بما يكفي لمواكبة ذلك لم تعد بيانات المؤسسة مناسبة تمامًا للتخزين القياسي ،
في حين نمت احتياجات التخزين والحوسبة بسرعة فائقة في العقود العديدة الماضية ، لم تتقدم الأجهزة التقليدية بما يكفي لمواكبة ذلك لم تعد بيانات المؤسسة مناسبة تمامًا للتخزين القياسي ،
وقد تستغرق قوة الحساب المطلوبة للتعامل مع معظم مهام تحليلات البيانات الضخمة أسابيع أو شهورًا ، أو ببساطة لا يمكن إكمالها على جهاز كمبيوتر قياسي للتغلب على هذا النقص ، تطورت العديد من التقنيات الجديدة لتشمل أجهزة كمبيوتر متعددة تعمل معًا
وتوزع قاعدة البيانات على آلاف الخوادم السلعية عندما تكون شبكة من أجهزة الكمبيوتر متصلة وتعمل معًا لإنجاز نفس المهمة ، تشكل أجهزة الكمبيوتر كتلة. يمكن اعتبار المجموعة كجهاز كمبيوتر واحد ولكن يمكنها تحسين الأداء والتوافر وقابلية التوسع بشكل كبير على جهاز واحد أكثر قوة وبتكلفة أقل
باستخدام أجهزة Apache Hadoop هو مثال على البنى التحتية للبيانات الموزعة التي تستفيد من المجموعات لتخزين ومعالجة كميات هائلة من البيانات ، وما الذي يمكّن بنية بحيرة البيانات.
عندما تفكر في Hadoop ، فكر في "التوزيع". يتكون Hadoop من ثلاثة مكونات رئيسية:
اولا Hadoop Distributed File System (HDFS) ، وهي طريقة لتخزين وتتبع بياناتك عبر محركات أقراص صلبة فعلية متعددة (موزعة)
اولا Hadoop Distributed File System (HDFS) ، وهي طريقة لتخزين وتتبع بياناتك عبر محركات أقراص صلبة فعلية متعددة (موزعة)

و؛ MapReduce ، إطار عمل لمعالجة البيانات عبر المعالجات الموزعة ومع ذلك ، مفاوض آخر عن الموارد (YARN) ، وهو إطار عمل لإدارة الكتلة ينظم توزيع أشياء مثل استخدام وحدة المعالجة المركزية والذاكرة وتخصيص النطاق الترددي للشبكة عبر أجهزة الكمبيوتر الموزعةبشكل خاص
تعد طبقة معالجة Hadoop ابتكارًا ملحوظًا بشكل خاص
ال: MapReduce هو نهج حسابي من خطوتين لمعالجة مجموعات بيانات كبيرة (متعددة تيرابايت أو أكبر) موزعة عبر مجموعات كبيرة من أجهزة السلع بطريقة موثوقة ومتسامحة مع الأخطاء تتمثل الخطوة الأولى في توزيع بياناتك عبر أجهزة كمبيوتر متعددة
ال: MapReduce هو نهج حسابي من خطوتين لمعالجة مجموعات بيانات كبيرة (متعددة تيرابايت أو أكبر) موزعة عبر مجموعات كبيرة من أجهزة السلع بطريقة موثوقة ومتسامحة مع الأخطاء تتمثل الخطوة الأولى في توزيع بياناتك عبر أجهزة كمبيوتر متعددة
الخطوة التالية هي دمج هذه النتائج بطريقة زوجية (تقليل). نشرت Google ورقة حول MapReduce في عام 2004 ، والتي اختارها مبرمجو Yahoo الذين قاموا بتطبيقها في بيئة Apache مفتوحة المصدر في عام 2006 ،
مما يوفر لكل شركة القدرة على تخزين حجم غير مسبوق من البيانات باستخدام الأجهزة على الرغم من وجود العديد من التطبيقات مفتوحة المصدر للفكرة ، إلا أن اسم العلامة التجارية لـ Google MapReduce عالق ، مثل Jacuzzi أو Kleenex.
تم تصميم Hadoop للحسابات التكرارية ، ومسح كميات هائلة من البيانات في عملية واحدة من القرص ، وتوزيع المعالجة عبر عقد متعددة ، وتخزين النتائج مرة أخرى على القرص يمكن إكمال الاستعلام عن zettabytes من البيانات المفهرسة
التي تستغرق 4 ساعات للتشغيل في بيئة مستودع بيانات تقليدية في غضون 10-12 ثانية باستخدام Hadoop و HBase. عادةً ما يتم استخدام Hadoop لإنشاء نماذج تحليلات معقدة أو تطبيقات تخزين بيانات كبيرة الحجم مثل التحليلات بأثر رجعي والتنبؤ ، والتعلم الآلي ومطابقة الأنماط ،
تم بناء Apache Spark في عام 2012 Spark هي أداة معالجة بيانات متوازية تم تحسينها للسرعة والكفاءة من خلال معالجة البيانات في الذاكرة وفقًا لمبدأ MapReduce ولكنه يعمل بشكل أسرع من خلال إكمال معظم العمليات الحسابية في الذاكرة والكتابة على القرص فقط عندما تكون الذاكرة ممتلئة
Hadoop و Spark
ليسا التقنيات الوحيدة التي تستفيد من المجموعات لمعالجة كميات كبيرة من البيانات هناك طريقة حسابية شائعة أخرى لمعالجة الاستعلام الموزع تسمى المعالجة المتوازية الضخمة (MPP) على غرار MapReduce ، يوزع MPP معالجة البيانات عبر عقد متعددة ، وتعالج العقد البيانات بالتوازي
ليسا التقنيات الوحيدة التي تستفيد من المجموعات لمعالجة كميات كبيرة من البيانات هناك طريقة حسابية شائعة أخرى لمعالجة الاستعلام الموزع تسمى المعالجة المتوازية الضخمة (MPP) على غرار MapReduce ، يوزع MPP معالجة البيانات عبر عقد متعددة ، وتعالج العقد البيانات بالتوازي
تحتوي بعض قواعد بيانات MPP ، مثل Pivotal Greenplum ، على مكتبات تعلم آلي ناضجة تسمح بالتحليلات داخل قاعدة البيانات ومع ذلك ، كما هو الحال مع RDBMS التقليدية ، فإن معظم قواعد بيانات MPP لا تدعم البيانات غير المهيكلة ، وحتى البيانات المنظمة
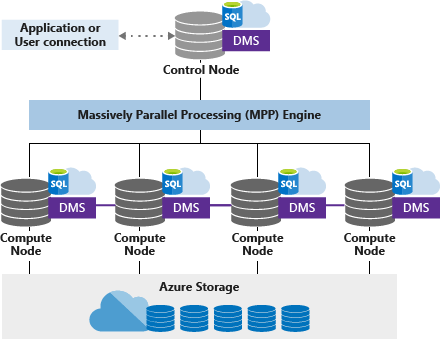
سوف تتطلب بعض المعالجة لتلائم البنية التحتية MPP لذلك ، يستغرق الأمر وقتًا وموارد إضافية لإعداد خط أنابيب البيانات لقاعدة بيانات MPP.
قواعد بيانات MPP هي متوافقة مع نطام القواعد ACID وتوفر سرعة أسرع بكثير من RDBMS التقليدية ، وعادة ما يتم توظيفها في حلول تخزين بيانات المؤسسة المتطورة مثل Amazon Redshift و Pivotal Greenplum و Snowflake.
كمثال على الصناعة ، تتلقى بورصة نيويورك ما بين أربعة إلى خمسة تيرابايت من البيانات يوميًا وتجري تحليلات معقدة ومراقبة السوق وتخطيط السعة والمراقبة كانت الشركة تستخدم قاعدة بيانات تقليدية لا يمكنها التعامل مع عبء العمل
، الأمر الذي يستغرق ساعات للتحميل وكانت سرعة الاستعلام ضعيفة أدى الانتقال إلى قاعدة بيانات MPP إلى تقليل وقت تشغيل التحليل اليومي بمقدار ثماني ساعات.
Cloud Services الخدمات السحابية
من الابتكارات الأخرى التي حولت بالكامل قدرات تحليلات البيانات الضخمة للمؤسسة ظهور الخدمات السحابية في الأيام التي سبقت توفر الخدمات السحابية ، كان على الشركات شراء حلول تخزين البيانات والتحليلات في أماكن العمل من بائعي البرامج والأجهزة
من الابتكارات الأخرى التي حولت بالكامل قدرات تحليلات البيانات الضخمة للمؤسسة ظهور الخدمات السحابية في الأيام التي سبقت توفر الخدمات السحابية ، كان على الشركات شراء حلول تخزين البيانات والتحليلات في أماكن العمل من بائعي البرامج والأجهزة
وعادة ما تدفع رسوم ترخيص البرامج الدائمة ورسوم الصيانة السنوية للأجهزة والخدمات. علاوة على ذلك ، توجد تكاليف الطاقة والتبريد والأمن والحماية من الكوارث وموظفي تكنولوجيا المعلومات ، وما إلى ذلك ، لبناء وصيانة البنية التحتية في أماكن العمل.
حتى عندما كان من الممكن تقنيًا تخزين ومعالجة البيانات الضخمة ، وجدت معظم الشركات أن القيام بذلك على نطاق واسع باهظ التكلفة يتطلب التوسع في البنية التحتية المحلية أيضًا عملية تصميم وشراء واسعة النطاق ، والتي تستغرق وقتًا طويلاً للتنفيذ وتتطلب رأس مالًا كبيرًا مقدمًا
بدأ النموذج المحلي يفقد حصته في السوق بسرعة عندما تم تقديم الخدمات السحابية في أواخر العقد الأول من القرن الحادي والعشرين - نما سوق الخدمات السحابية العالمية بنسبة 15٪ سنويًا في العقد الماضي توفر منصات الخدمات السحابية اشتراكات في مجموعة متنوعة من الخدمات
(من الحوسبة الافتراضية إلى البنية التحتية للتخزين إلى قواعد البيانات) ، والتي يتم تقديمها عبر الإنترنت على أساس الدفع أولاً بأول ، مما يوفر للعملاء وصولاً سريعًا إلى التخزين المرن ومنخفض التكلفة ، يتحمل مقدمو الخدمات السحابية مسؤولية جميع عمليات شراء الأجهزة والبرامج وصيانتها
، وعادة ما يكون لديهم شبكة واسعة من الخوادم وموظفي الدعم لتقديم خدمات موثوق اكتشفت العديد من الشركات أنها يمكن أن تقلل التكاليف بشكل كبير وتحسن الكفاءات التشغيلية من خلال الخدمات السحابية ، وتكون قادرة على تطوير منتجاتها وإنتاجها بسرعة أكبر باستخدام موارد السحابة الجاهزة
عن طريق إزالة الوقت والتكاليف المقدمة الالتزام ببناء البنية التحتية المحلية ، كما تعمل الخدمات السحابية على تقليل الحواجز التي تحول دون اعتماد أدوات البيانات الضخمة وتحليلات البيانات الضخمة التي تم إضفاء الطابع الديمقراطي عليها بشكل فعال للشركات الصغيرة والمتوسطة الحجم.
بناء البنية التحتية لعلوم البيانات من البداية إلى النهاية
يتضمن بناء منتج علم بيانات قابل للتطبيق أكثر بكثير من مجرد بناء نموذج للتعلم الآلي باستخدام scikit-Learn والتخلص منه وتحميله على الخادم يتطلب فهم كيفية عمل جميع أجزاء النظام البيئي للمؤسسة معًا
يتضمن بناء منتج علم بيانات قابل للتطبيق أكثر بكثير من مجرد بناء نموذج للتعلم الآلي باستخدام scikit-Learn والتخلص منه وتحميله على الخادم يتطلب فهم كيفية عمل جميع أجزاء النظام البيئي للمؤسسة معًا
بدءًا من مكان / كيف تتدفق البيانات إلى فريق البيانات ، والبيئة التي تتم فيها معالجة / تحويل البيانات ، واتفاقيات المؤسسة لتصور / عرض البيانات ، وكيف سيتم تحويل إخراج النموذج كمدخل لبعض تطبيقات المؤسسة الأخرى تتضمن الأهداف الرئيسية بناء عملية يسهل صيانتها ،
حيث يمكن تكرار النماذج والأداء قابل للتكرار ، ويمكن بسهولة فهم مخرجات النموذج وتصورها لأصحاب المصلحة الآخرين حتى يتمكنوا من اتخاذ قرارات عمل مستنيرة يتطلب تحقيق هذه الأهداف اختيار الأدوات المناسبة ، بالإضافة إلى فهم ما يفعله الآخرون في الصناعة وأفضل الممارسات.
دعنا نوضح سيناريو:
لنفترض أنك قد تم تعيينك للتو كعالم بيانات رائد لبدء تشغيل تطبيق توصيات العطلات الذي من المتوقع أن يجمع مئات الجيجابايت من كلا التنظيمين (ملفات تعريف العملاء ودرجات الحرارة والأسعار وسجلات المعاملات) وغير المهيكلة (العملاء) المشاركات / التعليقات وملفات الصور)
لنفترض أنك قد تم تعيينك للتو كعالم بيانات رائد لبدء تشغيل تطبيق توصيات العطلات الذي من المتوقع أن يجمع مئات الجيجابايت من كلا التنظيمين (ملفات تعريف العملاء ودرجات الحرارة والأسعار وسجلات المعاملات) وغير المهيكلة (العملاء) المشاركات / التعليقات وملفات الصور)
بيانات من المستخدمين يوميًا ستحتاج نماذجك التنبؤية إلى إعادة تدريبها ببيانات جديدة أسبوعيًا وتقديم توصيات فورًا عند الطلب نظرًا لأنك تتوقع أن يحقق تطبيقك نجاحًا كبيرًا ، فيجب أن تكون سعة جمع البيانات والتخزين والتحليلات قابلة للتطوير بدرجة كبيرة
كيف ستصمم عملية علم البيانات وتنتج النماذج الخاصة بك؟
ما هي الأدوات التي ستحتاجها لإنجاز المهمة؟ نظرًا لأن هذه شركة ناشئة وأنت الرائد
- وربما الوحيد - عالم البيانات ، فإن عليك اتخاذ هذه القرارات.
ما هي الأدوات التي ستحتاجها لإنجاز المهمة؟ نظرًا لأن هذه شركة ناشئة وأنت الرائد
- وربما الوحيد - عالم البيانات ، فإن عليك اتخاذ هذه القرارات.
أولاً ، يجب عليك معرفة كيفية إعداد مسار البيانات الذي يأخذ البيانات الأولية من مصادر البيانات ، ويعالج البيانات ، ويغذي البيانات المعالجة إلى قواعد البيانات يتميز خط أنابيب البيانات المثالي بوقت استجابة منخفض للحدث
(القدرة على الاستعلام عن البيانات بمجرد جمعها) ؛
قابلية التوسع
القدرة على التعامل مع كمية هائلة من البيانات مع توسع منتجك
الاستعلام التفاعلي
يدعم كلاً من الاستعلامات المجمعة والاستعلامات التفاعلية الأصغر التي تسمح لعلماء البيانات باستكشاف الجداول والمخططات
قابلية التوسع
القدرة على التعامل مع كمية هائلة من البيانات مع توسع منتجك
الاستعلام التفاعلي
يدعم كلاً من الاستعلامات المجمعة والاستعلامات التفاعلية الأصغر التي تسمح لعلماء البيانات باستكشاف الجداول والمخططات
الإصدار
القدرة على إجراء تغييرات على خط الأنابيب دون خفض خط الأنابيب وفقدان البيانات
المراقبة
يجب أن يصدر خط الأنابيب تنبيهات عندما تتوقف البيانات عن الدخول
والاختبار
القدرة على اختبار خط الأنابيب دون انقطاع
القدرة على إجراء تغييرات على خط الأنابيب دون خفض خط الأنابيب وفقدان البيانات
المراقبة
يجب أن يصدر خط الأنابيب تنبيهات عندما تتوقف البيانات عن الدخول
والاختبار
القدرة على اختبار خط الأنابيب دون انقطاع
ربما الأهم من ذلك ، أنه من الأفضل عدم التدخل في العمليات التجارية اليومية - على سبيل المثال ، سوف تتسبب في مشاكل إذا تسبب النموذج الجديد الذي تختبره في توقف قاعدة البيانات التشغيلية الخاصة بك عادةً ما يكون إنشاء خط أنابيب البيانات وصيانته هو مسؤولية مهندس البيانات
زيد من التفاصيل ، تحتوي هذه المقالة على نظرة عامة ممتازة على بناء خط أنابيب البيانات للشركات الناشئة
ولكن يجب أن يكون عالم البيانات على الأقل على دراية بالعملية وقيودها والأدوات اللازمة للوصول إلى البيانات المعالجة للتحليل.
towardsdatascience.com
ولكن يجب أن يكون عالم البيانات على الأقل على دراية بالعملية وقيودها والأدوات اللازمة للوصول إلى البيانات المعالجة للتحليل.
towardsdatascience.com
بعد ذلك ، عليك أن تقرر ما إذا كنت تريد إعداد بنية أساسية محلية أو استخدام الخدمات السحابية بالنسبة لبدء التشغيل ، فإن الأولوية القصوى هي توسيع نطاق جمع البيانات دون توسيع نطاق الموارد التشغيلية كما ذكرنا سابقًا ، تتطلب البنية التحتية المحلية تكاليف ضخمة مقدمًا وصيانة
، لذلك تميل الخدمات السحابية إلى أن تكون خيارًا أفضل للشركات الناشئة. تتيح الخدمات السحابية التوسع لمطابقة الطلب وتتطلب الحد الأدنى من جهود الصيانة حتى يتمكن فريقك الصغير من التركيز على المنتج والتحليلات بدلاً من إدارة البنية التحتية.
من أجل اختيار مقدم خدمة سحابية ، عليك أولاً إنشاء البيانات التي تحتاجها للتحليلات ، وقواعد البيانات والبنية التحتية للتحليلات الأكثر ملاءمة لأنواع البيانات هذه نظرًا لوجود بيانات منظمة وغير منظمة في خط أنابيب التحليلات
فقد ترغب في إعداد كل من مستودع البيانات وبحيرة البيانات من الأمور المهمة التي يجب مراعاتها لعلماء البيانات ما إذا كانت طبقة التخزين تدعم أدوات البيانات الضخمة اللازمة لبناء النماذج وما إذا كانت قاعدة البيانات توفر تحليلات فعالة داخل قاعدة البيانات على سبيل المثال
لا يمكن استخدام بعض مكتبات ML مثل Spark's MLlib بشكل فعال مع قواعد البيانات كواجهة رئيسية للبيانات - يجب تفريغ البيانات من قاعدة البيانات قبل أن يتم تشغيلها ، مما قد يستغرق وقتًا طويلاً للغاية اذا حجم البيانات كبيرا
بالنسبة لعلوم البيانات في السحابة ، يعمل معظم موفري الخدمات السحابية بجد لتطوير قدراتهم الأصلية للتعلم الآلي التي تسمح لعلماء البيانات ببناء ونشر نماذج التعلم الآلي بسهولة مع البيانات المخزنة في النظام الأساسي الخاص بهم
(أمازون لديها SageMaker ، و Google لديها BigQuery ML ، و Microsoft لديها Azure Machine Learning). لكن مجموعات الأدوات لا تزال قيد التطوير وغالبًا ما تكون غير مكتملة: على سبيل المثال ، لا يدعم BigQuery ML حاليًا سوى الانحدار الخطي والانحدار اللوجستي الثنائي ومتعدد الفئات
وتجميع الوسائل واستيراد نموذج TensorFlow إذا قررت استخدام هذه الأدوات ، فسيتعين عليك اختبار قدراتها بدقة للتأكد من أنها تفعل ما تريد منها القيام به.
رابط الموضوع الأصلي
kdnuggets.com
هذا الثريد يعتبر شامل لأهم مفاهيم قواعد البيانات من البداية للنهاية اتمني أن تكونو استفدتم منه بقدر الإمكان ♥️
kdnuggets.com
هذا الثريد يعتبر شامل لأهم مفاهيم قواعد البيانات من البداية للنهاية اتمني أن تكونو استفدتم منه بقدر الإمكان ♥️
جاري تحميل الاقتراحات...