

لنفترض أن لدينا مركزين لفحص فيروس #كورونا
الأول: دقته 69%
والثاني: دقته 29%
أيهما ستختار لإجراء الفحص؟
تعالوا نتعرف على قياسات تقييم أداء خوارزميات #تعلم_الآلة (Machine Learning) ومعايير اختيار كل قياس ، تابع ربما تُغير رأيك وخيارك في نهاية التغريدات!
#علم_البيانات
الأول: دقته 69%
والثاني: دقته 29%
أيهما ستختار لإجراء الفحص؟
تعالوا نتعرف على قياسات تقييم أداء خوارزميات #تعلم_الآلة (Machine Learning) ومعايير اختيار كل قياس ، تابع ربما تُغير رأيك وخيارك في نهاية التغريدات!
#علم_البيانات
تتعلم خوارزميات #تعلم_الآلة بالبيانات ونقوم بتقييم تعلمها باستخدام مجموعة من القياسات من ضمنها وأشهرها الدقة (accuracy) ، ولكن هذا القياس يبدو مضلل في بعض الأحيان كما سنشاهد في تقييم مركزي فحص #كورونا ، لذا مهم جداً اختيار القياس المناسب لتقييم نموذج التعلم.. ولكن بناءً على ماذا؟
من أهم المعايير هي تكلفة الخطأ ، الخطأ في تصنيف ايميل وصلنا على أنه spam وهو ليس spam ليس مثل خطورة تصنيف أحدهم على أنه غير مصاب بـ #كورونا وهو في الحقيقة مصاب!
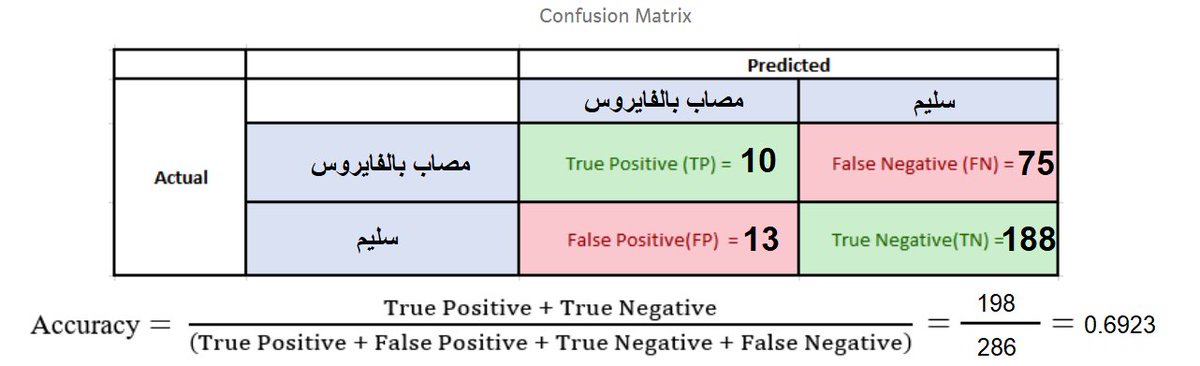
لنرجع لمركز الفحص الأول والذي تم تقييم دقته accuracy بـ 69% وننظر في النتائج التفصيلية لفحوصات هذا المركز
- شُخص 10 على أنهم مصابين وهم بالفعل مصابين
- شخص 13 على أنهم مصابين وهم فعلياً سليمين
- شخص 75 على أنهم سليمين وهم فعلياً مصابين
- شخص 118 على أنهم سليمين وهم بالفعل سليمين
- شُخص 10 على أنهم مصابين وهم بالفعل مصابين
- شخص 13 على أنهم مصابين وهم فعلياً سليمين
- شخص 75 على أنهم سليمين وهم فعلياً مصابين
- شخص 118 على أنهم سليمين وهم بالفعل سليمين
في المقابل تفاصيل نتائج الفحص للمركز الثاني والذي تم تقييم دقته accuracy بـ 29% كانت كالتالي
- شُخص 85 على أنهم مصابين وهم بالفعل مصابين
- شخص 201 على أنهم مصابين وهم فعلياً سليمين
- شخص 0 على أنهم سليمين وهم فعلياً مصابين
- شخص 0 على أنهم سليمين وهم بالفعل سليمين
- شُخص 85 على أنهم مصابين وهم بالفعل مصابين
- شخص 201 على أنهم مصابين وهم فعلياً سليمين
- شخص 0 على أنهم سليمين وهم فعلياً مصابين
- شخص 0 على أنهم سليمين وهم بالفعل سليمين

اذا نظرنا إلى مصفوفة الدقة (Confusion Matrix) للمركز الأول سنجد أن هذا المركز استطاع التعرف على 10 فقط من أصل 85 مصاب وهذا مانطلق عليه Recall ويعادل 12%، بينما المركز الثاني أستطاع التعرف على 85 مصاب من أصل 85 مصاب يعني 100%، بمعنى أن المركز الثاني نجح في التعرف على جميع المصابين

يقيس precision الإيجابية الصحيحة وهي نسبة من تم تصنيفهم إيجابي على مجموع الإيجابيات الحقيقية.
في المركز الأول 10 تم تصنيفهم إيجابي من بين 23 إيجابي حقيقي وبالتالي precision تساوي 43%
في المركز الثاني 85 تم تصنيفهم إيجابي من بين 286 إيجابي حقيقي وبالتالي precision تساوي 29%
في المركز الأول 10 تم تصنيفهم إيجابي من بين 23 إيجابي حقيقي وبالتالي precision تساوي 43%
في المركز الثاني 85 تم تصنيفهم إيجابي من بين 286 إيجابي حقيقي وبالتالي precision تساوي 29%

تكمن أهمية قياس Recall حينما تكون تكلفة السلبيات الكاذبة (False Negatives) عالية، بينما تكمن أهمية Precision حينما تكون تكلفة الإيجابيات الكاذبة (False Positives) مرتفعة.
برأيكم أيهم أهم مع فحص #كورونا سلبي كاذب (مصاب يُصنف على أنه سليم) أم إيجابي كاذب (سليم يُصنف على أنه مصاب)؟
برأيكم أيهم أهم مع فحص #كورونا سلبي كاذب (مصاب يُصنف على أنه سليم) أم إيجابي كاذب (سليم يُصنف على أنه مصاب)؟
المركز الأول الذي دقته 69% صنف 75 مصاب فعلي بـ #كورونا على أنهم سليمين، بينما المركز الثاني الذي دقته 29% لم يصنف أي شخص مصاب على أنه سليم.
تكلفة السلبيات الكاذبة هنا عالية ، ونعني بها الـ 75 مصاب الذي تم تشخيصهم سليمين وتُركوا طلقاء دون حجر مما قد يتسبب في نقل الفايروس لآخرين!
تكلفة السلبيات الكاذبة هنا عالية ، ونعني بها الـ 75 مصاب الذي تم تشخيصهم سليمين وتُركوا طلقاء دون حجر مما قد يتسبب في نقل الفايروس لآخرين!
الدقة accuracy هنا مضللة ، رغم ارتفاع دقة المركز الأول إلا أن اخطاءه التصنيفية كارثية ، والمركز الثاني رغم دقته المنخفضة إلا أن اخطاءه غير كارثية ، تُرى ماهو المقياس المناسب في هذه الحالة؟
F1 score
قياس يجمع بين خاصيتي الدقة والاستدعاء ليكافأ المصيب ويعاقب المخطيء
F1 score
قياس يجمع بين خاصيتي الدقة والاستدعاء ليكافأ المصيب ويعاقب المخطيء
حينما نحسب F1 score للمركز الأول نجدها 18.5%
بينما قياس F1 score للمركز الثاني يساوي 45%
لاحظوا أن هذا القياس عاقب المركز الأول لاخطاءه الكارثية المكلفة في السلبيات الكاذبة (مصاب يُصنف على أنه سليم)، وكافأ المركز الثاني لدقته في تفادي تلك السلبيات
بينما قياس F1 score للمركز الثاني يساوي 45%
لاحظوا أن هذا القياس عاقب المركز الأول لاخطاءه الكارثية المكلفة في السلبيات الكاذبة (مصاب يُصنف على أنه سليم)، وكافأ المركز الثاني لدقته في تفادي تلك السلبيات

نلاحظ أن قياس F1 score أعطى الأفضلية للمركز الثاني في عمليات الفحص ، لذا فإن خيار الذهاب للمركز الثاني للفحص من #كورونا أفضل من الذهاب للمركز الأول .. ولكن متى نستخدم مقياس الدقة accuracy ومتى نستخدم F1 score ؟
يتم استخدام مقياس الدقة حينما تكون أهمية الإيجابيات والسلبيات الحقيقة متقاربة في الأهمية ، بينما يعطي قياسF1 score نتيجة أفضل وأكثر وضوحاً في حالة اهتمامنا أكثر بالسلبيات الكاذبة (مثل فحص كورونا) أو الإيجابيات الزائفة مثل السماح لغير المصرح له بالدخول لموقع معين
يعطي الـ accuracy نتيجة مفيدة حينما تكون الأصناف متوازنة (balance dataset) أما في حالة عدم توازنها (imbalance dataset) يكون F1 score مقياساً أفضل.
مثلاً في تصنيف الايميلات سأقوم ببناء نموذج يصنف كل الرسائل أنها ليست spam ، الدقة ستكون 98% (ببساطة لأن 98% من الرسائل ليست سبام!)
مثلاً في تصنيف الايميلات سأقوم ببناء نموذج يصنف كل الرسائل أنها ليست spam ، الدقة ستكون 98% (ببساطة لأن 98% من الرسائل ليست سبام!)
بشكل عام معظم مشاكل التصنيف الواقعية يكون توزيع الفئات (الأصناف) فيها غير متوازن (imbalance) ، وبالتالي فإن مقياس F1 score هو المقياس الأفضل لتقييم نماذجنا.
للمزيد بإمكانكم الرجوع للروابط التالية:
machinelearningmastery.com
medium.com
للمزيد بإمكانكم الرجوع للروابط التالية:
machinelearningmastery.com
medium.com
جاري تحميل الاقتراحات...