


2.
في حديثي السابق تكلمت عن البرمجة باستخدام MapReduce
وهي أساس لعملاق البيانات Hadoop
وسأتحدث اليوم عن Spark
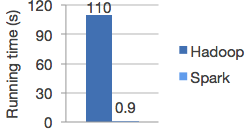
برمجيآ.. وهو الأكثر استخدامآ نظرآ للسرعة العالية High Performance
تقريبآ 100 مرة مقارنة ب Hadoop (MapReduce)
كما هو مرفق
في حديثي السابق تكلمت عن البرمجة باستخدام MapReduce
وهي أساس لعملاق البيانات Hadoop
وسأتحدث اليوم عن Spark
برمجيآ.. وهو الأكثر استخدامآ نظرآ للسرعة العالية High Performance
تقريبآ 100 مرة مقارنة ب Hadoop (MapReduce)
كما هو مرفق
3.
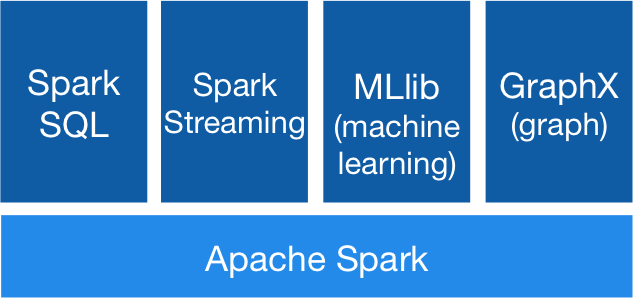
ماهو Spark
*عبارة عن بيئة مصممة لتحليل ومعالجة البيانات الضخمة بشكل سريع جدآ
يكتب بلغات مثل Python , Java, Scala
يمكن أن يعمل Patch
بمعنى بيانات مخرنة
او Streaming
بمعنى تحليل مباشر لبيانات جارية
*يمكن استخدامه كبيئة فرديه Stand Alone
أو Cluster Mode
بالنظم الموزعه وهو الأشهر
ماهو Spark
*عبارة عن بيئة مصممة لتحليل ومعالجة البيانات الضخمة بشكل سريع جدآ
يكتب بلغات مثل Python , Java, Scala
يمكن أن يعمل Patch
بمعنى بيانات مخرنة
او Streaming
بمعنى تحليل مباشر لبيانات جارية
*يمكن استخدامه كبيئة فرديه Stand Alone
أو Cluster Mode
بالنظم الموزعه وهو الأشهر
4.
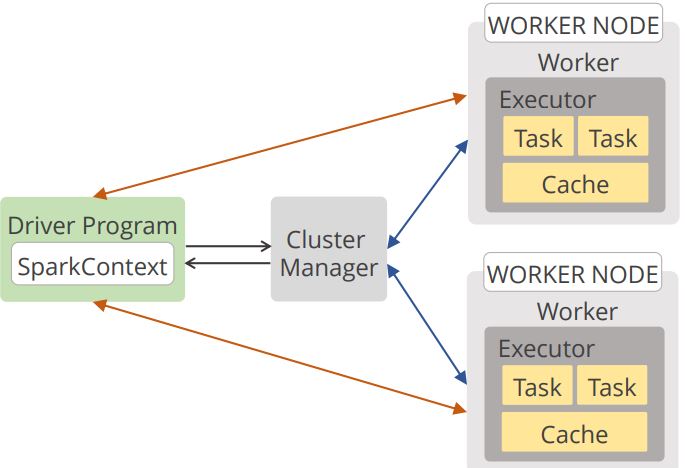
سبارك بيئة تعمل بطريقة النظم الموزعة وهي الطريقة المناسبة في البيانات الضخمة
بمعنى تقسيم البيانات الكبيرة الى بيانات أصغر او تقسيم المشكلة الكبيرة إلى مشاكل صغيرة ثم معالجتها على التوازي(بنفس الوقت)
ولكن نحتاج تفصيل أكثر
سبارك بيئة تعمل بطريقة النظم الموزعة وهي الطريقة المناسبة في البيانات الضخمة
بمعنى تقسيم البيانات الكبيرة الى بيانات أصغر او تقسيم المشكلة الكبيرة إلى مشاكل صغيرة ثم معالجتها على التوازي(بنفس الوقت)
ولكن نحتاج تفصيل أكثر
5.
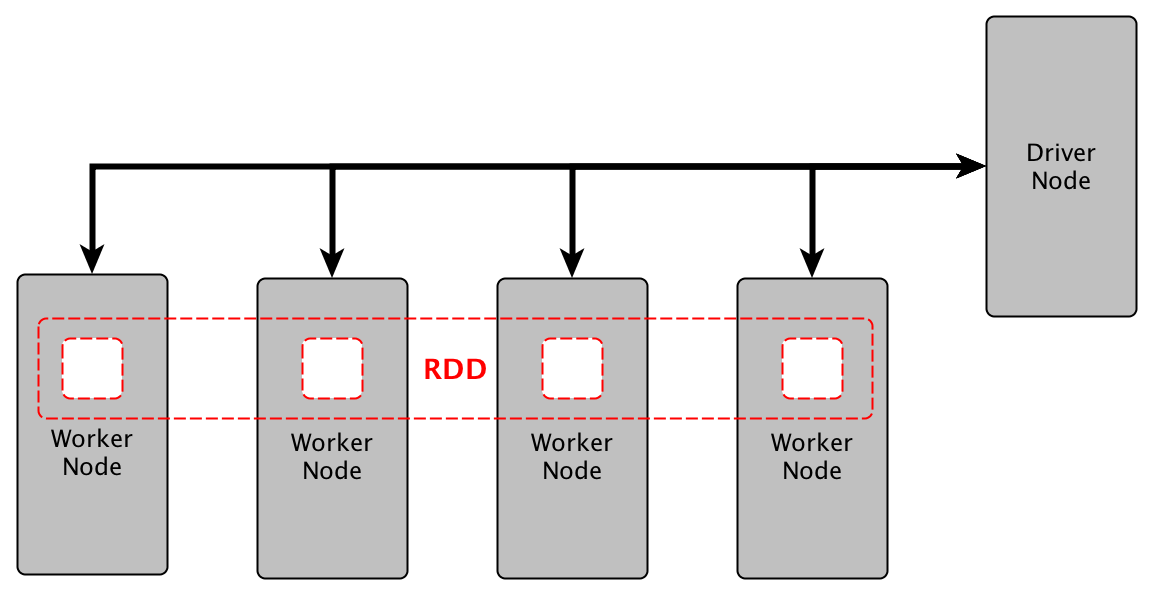
تم تطوير سبارك في جامعة كاليفورنيا في أمريكا Berkeley
وهو أداة تعتمد برمجيآ على فكرة RDD
resilient distributed dataset (RDD),
تم تطوير سبارك في جامعة كاليفورنيا في أمريكا Berkeley
وهو أداة تعتمد برمجيآ على فكرة RDD
resilient distributed dataset (RDD),
6.
RDD
فكرة مختلفة تماما عن البرمجه ب MapReduce الذي تحدثت عنه في ثريد سابق
فكرة RDD بشكل مبسط هي
In memory Cashing
وهو سر من أسرار تفوق سبارك على هادوب في السرعة
RDD
فكرة مختلفة تماما عن البرمجه ب MapReduce الذي تحدثت عنه في ثريد سابق
فكرة RDD بشكل مبسط هي
In memory Cashing
وهو سر من أسرار تفوق سبارك على هادوب في السرعة

8.
البرمجة في البيانات الضخمة هي مثل البرمجة في اللغات الاخرى ولكنها تحتاج معرفة أكبر ب
*الكلاود
*النظم الموزعة
*لغات مثل بايثون،جافا، سكالا
*لنكس/يونكس commands
..من خلال تجربتي فإن أفضل بيئة سواء ل Spark / Hadoop
هو أمازون كلاود Ec2
وسأشرح التجربة قريبا
مرفق أشهر الكتب للفائدة
البرمجة في البيانات الضخمة هي مثل البرمجة في اللغات الاخرى ولكنها تحتاج معرفة أكبر ب
*الكلاود
*النظم الموزعة
*لغات مثل بايثون،جافا، سكالا
*لنكس/يونكس commands
..من خلال تجربتي فإن أفضل بيئة سواء ل Spark / Hadoop
هو أمازون كلاود Ec2
وسأشرح التجربة قريبا
مرفق أشهر الكتب للفائدة


جاري تحميل الاقتراحات...