

حالما يتم الإعلان عن توفر وظيفة معينة، تتراكم العشرات بل المئات من السير الذاتية، فلترة هذه السير لاختيار المناسب منها عملية شاقة ومكلفة، تُرى هل يستطيع #علم_البيانات مساعدة الموارد البشرية في حل هذه المشكلة؟
تعالوا نتعرف على حكاية Raman مع صديقه الباحث عن موظفين!
تعالوا نتعرف على حكاية Raman مع صديقه الباحث عن موظفين!

يقول رامان: حصل أحد الأصدقاء مؤخراَ على مشروع تطلب منه تعيين موظفين في تخصص #علم_البيانات، وضع إعلان على LinkedIn وتفاجأ بوصول مايقارب 200 سيرة ذاتية!، حينما قابلته سألني: هل هناك طريقة لاختيار أفضل السير الذاتية من بين الـ 200 سيرة ذاتية بطريقة أسرع من المرور يدوياً عليها؟
يقول رامان: متطلبات صديقي في المرشح الأول بأن يكون شخص لديه خبرة في #التعلم_العميق مع خوازميات #تعلم_الآلة ، ومرشح آخر لديه مجموعة من مهارات العمل على #البيانات_الضخمة أو #هندسة_البيانات مثل الخبرة في مجال Scala و AWS و Dockers و Kubernetes ، ...إلخ
قام رامان باستخدام منهجية من 3 خطوات:
1⃣بناء قاموس أو جدول يحتوي على مجموعة كلمات تمثل المهارات المطلوبةفي كل وظيفة
2⃣ بناء خوارزمية NLP لمسح كل سيرة ذاتية للبحث عن الكلمات التي تم تعريفها في القاموس
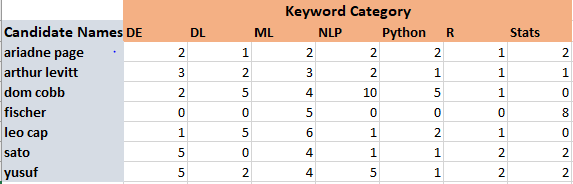
3⃣ حساب تكرار ظهور الكلمات في كل فئة لكل مترشح، كما في الجدول المرفق
1⃣بناء قاموس أو جدول يحتوي على مجموعة كلمات تمثل المهارات المطلوبةفي كل وظيفة
2⃣ بناء خوارزمية NLP لمسح كل سيرة ذاتية للبحث عن الكلمات التي تم تعريفها في القاموس
3⃣ حساب تكرار ظهور الكلمات في كل فئة لكل مترشح، كما في الجدول المرفق

قام رامان بالبحث عن مكتبة تساعده في مطابقة الكلمات، ووجد Spacy، يقول رامان: لحسن حظي أن السير الذاتية للمتقدمين كانت كلها بصيغة pdf، لذلك قررت فحص حزمتين لقراءة ملفات pdf وهي PDFminer و PyPDF2 ، واخترت الاخيرة ، ولتنفيذ منهجيتي استخدمت Python و لتصوير البيانات استخدمت Matplotlib
استخدم رامان ملف أكسل لبناء قاموس الكلمات، ويقول بإمكان أي مطور استخدام نفس الكود البرمجي الذي طورته واستبدال فئات وكلمات ملف الأكسل حسب نوع وطبيعة الوظيفة المطلوبة، والصورة المرفقة تمثل الكلمات التي استخدمها رامان للقيام بمطابقة الكلمات/العبارات مع السير الذاتية للمتقدمين

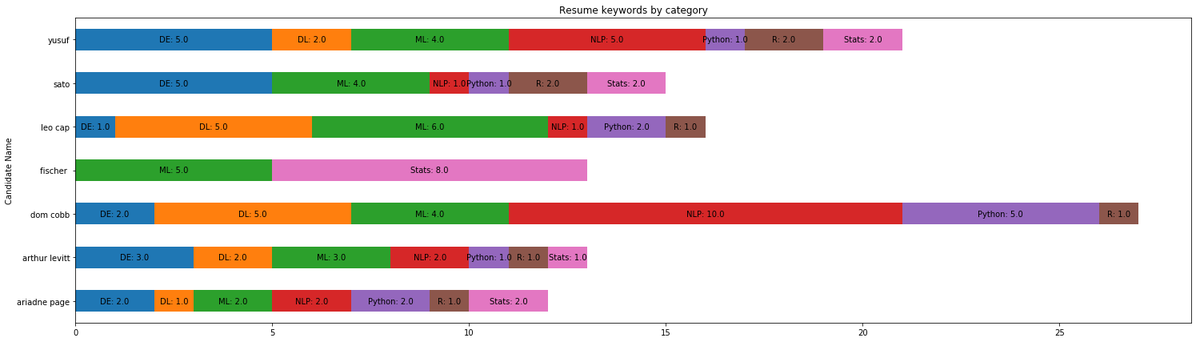
بعد تنفيذ الخوارزمية على الـ 200 سيرة ذاتية للمتقدمين كانت النتائج كما في الجدول المرفق، ولتسهيل قراءة النتائج قام رامان بتصويرها في شكل بياني، الرسم البياني يوضح أن المتقدمين Dom Cobb و Fischer متخصصين (تكرار عالي لكلمات stats و NLP)، بينما بقية المترشحين يبدون عاديين!
يقول رامان: فاجأت صديقي حقًا بالنتائج التي تحققت ووفرت عليه الكثير من الوقت والجهد، قام صديقي باختيار قائمة مختصرة تحتوي على 15 مترشح من أصل 200 سيرة ذاتية، كل هذا تم بتشغيل كود برمجي بسيط لا يكاد يتجاوز 130 سطر!
خلاصة التجربة: ربما العديد من الشركات تستخدم بالفعل رموزاً للفحص الأولي للمرشحين، لذا يُنصح بتخصيص السيرة الذاتية للمتطلبات الوظيفية المحددة باستخدام الكلمات الأساسية المطلوبة، أما بالنسبة للموارد البشرية بإمكانهم الاعتماد على #علم_البيانات لفلترة المرشحين بطريقة سهلة وسريعة
للمهتمين بإمكانكم الإطلاع على الكود البرمجي وتفاصيل التجربة على الرابط:
kdnuggets.com
وبالنسبة لمكتبة Spacy وميزة Phrase Matcher هنا تفاصيل عنها:
spacy.io
kdnuggets.com
وبالنسبة لمكتبة Spacy وميزة Phrase Matcher هنا تفاصيل عنها:
spacy.io
جاري تحميل الاقتراحات...